Josep Marco-Pallarés y Juan Lupiáñez tuvieron la amabilidad de invitarme a dar un seminario en los másteres que dirigen en la Universitat de Barcelona y la Universidad de Granada, respectivamente. Intenté convencer a los estudiantes de que no deben creerse todo lo que lean en un artículo y les enseñé algunas herramientas estadísticas sencillas que permiten evaluar críticamente cómo de creíbles son los resultados de un estudio. Entre otras cosas, vimos cómo analizar la distribución de valores p, cómo hacer un funnel plot y cómo usar el test de exceso de resultados significativos. Si te interesan estos temas, puedes encontrar información sobre todas estas técnicas en las diapositivas del curso, incluyendo el código necesario para hacer los análisis en R y enlaces a otras aplicaciones online para detectar sesgos.
Category Archives: método científico y valores de la ciencia
Entrevista para El Mcguffin Educativo
Siempre me ha sorprendido que a los escépticos de nuestro país les preocupen tanto la homeopatía y las flores de Bach -que al fin y al cabo son libres de tomar o no- y sin embargo permanezcan indiferentes ante las prácticas pseudocientíficas a las que, lo quieran o no, someten a sus hijos en las escuelas. Es difícil encontrar una escuela donde no se utilicen los bits de inteligencia de Doman, basados en la idea de que con la estimulación adecuada, cualquier niño de menos de uno año de edad puede aprender a escribir, sumar y restar. Bajo el nombre de HERAT acaba de llegar a nuestro país un programa educativo que en el resto de los países se conoce como Brain Gym y se basa en ideas felices como que los niños aprenden mejor si beben seis vasos de agua al día (porque “la comida procesada no tiene agua”), o si se tocan los lóbulos de las orejas de cierta manera para favorecer la conexión de los hemisferios cerebrales a través del cuerpo calloso. No pasa nada si tu hijo tiene problemas de dislexia, autismo o TDAH –que por cierto, no existe– porque disponemos de sencillos métodos que curan todo esto y más a base de hacer ejercicios de percusión o escuchando música manipulada electrónicamente. Lógicamente, los cursillos donde se enseña esto hacen furor entre el profesorado. Los niños del siglo XXI ya no son introvertidos o extrovertidos; no se les dan bien o mal las matemáticas. Ahora son de hemisferio izquierdo o de hemisferio derecho; visuales, kinestésicos o auditivos; tienen inteligencias múltiples, cada uno las suyas. De hecho, los niños son ahora tan diferentes los unos de los otros que ya sólo tienen una cosa en común: Todos son genios. En fin. Entre tanta moda que va y viene sólo hay un puñado de valientes que se atreve a decirle al emperador que va desnudo. Y entre ellos, Albert Reverter brilla con luz propia. Así que cuando me preguntó si me dejaría entrevistar para su blog, El Mcguffin Educativo, la respuesta fue sencilla. El resultado, aquí.
Entrevista para UDIMA
Cada vez que quedo con Carmelo para tomar algo y charlar un rato, no sé si llegamos a solucionar los grandes problemas del mundo, pero a mí me parece que todo va un poco mejor. Nuestras conversaciones pierden algo de gracia si no tenemos delante una cerveza o una ración de bravas que nos hagan de espectadoras y comenten la jugada. Aun así, Carmelo quiso entrevistarme formalmente para la UDIMA y esto es lo que salió. Debo decir que sólo estoy de acuerdo con el titular los días impares, pero hoy lo es.
Cognitive biases, error management theory, and the reproducibility of research findings
The human mind is the end product of hundreds of thousands of years of relentless natural selection. You would expect that such an exquisite piece of software should be capable of representing reality in an accurate and objective manner. Yet decades of research in cognitive science show that we fall prey to all sorts of cognitive biases and that we systematically distort the information we receive. Is this the best evolution can achieve? A moment’s thought reveals that the final goal of evolution is not to develop organisms with exceptionally accurate representations of the environment, but to design organisms good at surviving and reproducing. And survival is not necessarily about being rational, accurate, or precise. The target goal is actually to avoid making mistakes with fatal consequences, even if the means to achieve this is to bias and distort our perception of reality. Read the post in Imperfect Cognitions.
Poniendo en contexto la replicabilidad de la psicología
Desde que se publicaron los resultados del Reproducibility Project: Psychology (RPP) las actitudes de la comunidad científica se han dividido entre quienes creen que es necesario cambiar radicalmente la forma en la que se hace investigación en nuestra disciplina y quienes consideran que la situación no es tan mala y que los métodos que se han venido utilizando hasta ahora han funcionado razonablemente bien. A falta de términos mejores –y ya que estamos en plena campaña electoral– llamaré a los primeros reformistas y a los segundos conservadores.
Uno de los argumentos más frecuentemente esgrimidos por los conservadores es que el fracaso a la hora de replicar un fenómeno no quiere decir necesariamente que ese fenómeno no exista. Si acaso, una réplica fallida revela que ese fenómeno sólo aparece en circunstancias muy concretas y que, tan pronto como se cambia algo en un estudio, el efecto desaparece. Por ejemplo, si hacemos un estudio sobre las actitudes de los blancos hacia las personas de otras razas, es muy probable que los resultados sean muy diferentes en países como EE.UU. que en Holanda o Australia. Si alguien no consigue replicar en Holanda un resultado que se observó inicialmente en EE.UU. esto no quiere decir que el hallazgo original fuera falso sino, simplemente, que sólo puede detectarse en circunstancias muy concretas.
Un trabajo recién publicado en la prestigiosa PNAS sugiere que los resultados negativos del RPP podrían deberse en buena parte a las dificultades para recrear el contexto de los experimentos originales. Los autores de este estudio pidieron a tres investigadores que leyeran los abstracts de los 100 estudios que se habían intentado replicar en el RPP y que, en base únicamente a esos textos, juzgaran hasta qué punto los fenómenos estudiados podrían depender del contexto en el que tenía lugar el estudio. Por ejemplo, se les pedía que estimaran si los resultados podrían depender de que el estudio se realizara en un momento concreto (por ejemplo, tiempos de recesión), en una comunidad étnica, racial o cultural concreta (por ejemplo, mezcla de diferentes razas, culturas individualistas), o en un entorno rural o urbano, entre otros aspectos.
 Los autores del estudio tomaron estas estimaciones de la importancia del contexto y analizaron hasta qué punto ayudaban a predecir si un experimento se replicaría o no. Los resultados más importantes se muestran en la figura adjunta. Lo que aquí se muestra es que, después de controlar estadísticamente algunas de las variables más importantes (por ejemplo, la potencia estadística de la réplica, la “sorpresividad” del efecto en cuestión), la sensibilidad al contexto seguía explicando una parte importante de la varianza. Estos datos vienen a confirmar que manteniendo constantes todos los demás factores, algunos fenómenos son más sensibles al contexto que otros y esa mayor sensibilidad determina que puedan ser fácilmente replicados o no.
Los autores del estudio tomaron estas estimaciones de la importancia del contexto y analizaron hasta qué punto ayudaban a predecir si un experimento se replicaría o no. Los resultados más importantes se muestran en la figura adjunta. Lo que aquí se muestra es que, después de controlar estadísticamente algunas de las variables más importantes (por ejemplo, la potencia estadística de la réplica, la “sorpresividad” del efecto en cuestión), la sensibilidad al contexto seguía explicando una parte importante de la varianza. Estos datos vienen a confirmar que manteniendo constantes todos los demás factores, algunos fenómenos son más sensibles al contexto que otros y esa mayor sensibilidad determina que puedan ser fácilmente replicados o no.
 No es ningún secreto que mis simpatías se decantan hacia el lado de los reformistas. Aunque valoro este tipo de trabajos y puedo apreciar su contribución, inevitablemente me despiertan sospechas. Ya he contestado aquí a quienes argumentan que los intentos fallidos de replicar un experimento se deben atribuir a moderadores y variables contextuales. Mi argumentación es idéntica en este caso. Puedo entender que unos fenómenos sean más delicados que otros y que requieran un mayor esfuerzo por parte del investigador para recrear las condiciones ideales; pero este argumento deja sin explicar la clara evidencia de sesgos de publicación y de p-hacking en los estudios originales del RPP. Uno de las gráficas que mejor lo demuestra es esta distribución de valores z elaborada por Richard Kunert. Un experimento tiene resultados significativos cuando su z es mayor de 1.96. Como puede verse en este gráfico, las puntuaciones z de los estudios originales del RPP es extremadamente irregular, con un pico muy pronunciado justo alrededor de 2. Esta distribución sugiere que ha habido sesgos de publicación (los estudios con z < 1.96 se han borrado del mapa) o malas prácticas (los estudios con z < 1.96 se han reanalizado una y otra vez hasta que por arte de magia se ha obtenido una z > 1.96). Nada de esto quiere decir que los autores del estudio en PNAS se equivoquen. Pero sospecho que representa sólo una parte de la historia. Una parte que puede resultar reconfortante, pero que tal vez nos ayude poco a mejorar la ciencia que hacemos.
No es ningún secreto que mis simpatías se decantan hacia el lado de los reformistas. Aunque valoro este tipo de trabajos y puedo apreciar su contribución, inevitablemente me despiertan sospechas. Ya he contestado aquí a quienes argumentan que los intentos fallidos de replicar un experimento se deben atribuir a moderadores y variables contextuales. Mi argumentación es idéntica en este caso. Puedo entender que unos fenómenos sean más delicados que otros y que requieran un mayor esfuerzo por parte del investigador para recrear las condiciones ideales; pero este argumento deja sin explicar la clara evidencia de sesgos de publicación y de p-hacking en los estudios originales del RPP. Uno de las gráficas que mejor lo demuestra es esta distribución de valores z elaborada por Richard Kunert. Un experimento tiene resultados significativos cuando su z es mayor de 1.96. Como puede verse en este gráfico, las puntuaciones z de los estudios originales del RPP es extremadamente irregular, con un pico muy pronunciado justo alrededor de 2. Esta distribución sugiere que ha habido sesgos de publicación (los estudios con z < 1.96 se han borrado del mapa) o malas prácticas (los estudios con z < 1.96 se han reanalizado una y otra vez hasta que por arte de magia se ha obtenido una z > 1.96). Nada de esto quiere decir que los autores del estudio en PNAS se equivoquen. Pero sospecho que representa sólo una parte de la historia. Una parte que puede resultar reconfortante, pero que tal vez nos ayude poco a mejorar la ciencia que hacemos.
__________
Van Bavel, J. J., Mende-Siedlecki, P., Brady, W. J., & Reinero, D. A. (2016). Contextual sensitivity in scientific reproducibility. Proceedings of the National Academy of Sciences of the United States of America, 113, 6454-6459.
La psicología al desnudo
Ayer por la noche, la prestigiosa revista Science publicaba bajo el título “Estimating the reproducibility of psychological science” los resultados del que sin duda será el estudio del año o de la década. Doscientos setenta investigadores de todo el mundo se pusieron de acuerdo para intentar replicar cien experimentos de psicología publicados originalmente en 2008 en tres de las más importantes revistas de psicología: Journal of Experimental Psychology: Learning, Memory and Cognition; Journal of Personality and Social Psychology; y Psychological Science. Tal y como reconocen los propios autores, no hay una única forma de estimar si un estudio ha replicado exitosamente los resultados de otro. Pero si tomamos como medida del éxito el simple hecho de si la réplica ha arrojado resultados estadísticamente significativos o no, entonces tan sólo el 36% de los estudios originales se ha replicado. El artículo y su abundante material suplementario están llenos de matices e información valiosa que habrá que desmenuzar y analizar con calma durante los próximos días. Pero aquí quiero quedarme únicamente con esa cifra aparentemente penosa: 36%.
Apenas publicado el artículo, los titulares de medio mundo se llenaban con la triste noticia de que sólo el 36% de los experimentos de psicología eran replicables. Pero, ¿es poco un 36%? Si te paras a pensarlo, esta pregunta es más difícil de responder de lo que parece. Sin duda, un 36% es mucho menos de lo que esperábamos y de lo que creemos deseable para cualquier ciencia sana. Pero si la pregunta se enfoca bajo otro ángulo y nos preguntamos si un 36% es una cifra normal o no para una disciplina científica, enseguida caeremos en la cuenta de que no tenemos absolutamente ninguna evidencia para responder a esta pregunta. Son varios los estudios de carácter estadístico que han sugerido que los datos publicados en las revistas son demasiado bonitos para ser cierto y que seguramente en torno al 50% o más de los resultados científicos son falsos positivos. Pero en su mayor parte estas estimaciones son sólo elucubraciones teóricas basadas en la estadística. Más allá de la especulación lo cierto es que, salvo por unos pocos estudios pequeños y poco sistemáticos, apenas tenemos datos empíricos sobre cómo de replicables son los resultados que se publican en las revistas científicas. De cualquier disciplina.
Durante una temporada, los blogs, periódicos y revistas se harán eco del titular fácil de que sólo uno de cada tres experimentos de psicología puede replicarse. Sin embargo, creo que no pasará mucho tiempo hasta que se le reconozca a la psicología el mérito de haber sido la primera disciplina en mostrar sus vergüenzas y reconocer que el rey va ligero de ropa. El artículo recién publicado en Science es el primer intento serio de explorar a gran escala la replicabilidad de los resultados científicos. Espero que le sigan muchos, dentro de la propia psicología y también en otras disciplinas, como el ya iniciado Cancer Biology Reproducibility Project. Preveo que pasado el tiempo, el artículo de estos 270 investigadores no será motivo de vergüenza para los psicólogos experimentales, sino que permanecerá como recordatorio de que un día esta pequeña disciplina se puso al frente de un movimiento llamado a revolucionar la ciencia que practicamos.
__________
Open Science Collaboration (2015). Estimating the reproducibility of psychological science. Science, 349, aac4716.
Bilingüismo y sus ventajas: ¿Exageración científica?
Se me ocurren muchas razones por las que merece la pena estudiar un nuevo idioma. Pero a juzgar por las conclusiones del artículo recién publicado por de Bruin, Treccani, y Della Sala (2015) en Psychological Science, tal vez deba tachar alguna de ellas de mi lista o al menos moverla más abajo. Durante los últimos años se ha hecho fuerte la idea de que el bilingüismo es una suerte de gimnasia mental que mejora diversas capacidades cognitivas, especialmente aquellas a las que se alude genéricamente con el nombre de control ejecutivo. Apenas puede uno abrir un volumen de cualquier revista de psicología sin encontrarse un artículo sobre el tema. Como no podría ser de otra forma, la idea se ha abierto camino rápidamente en la cultura popular y muy especialmente en el mundo de la educación. Los medios de comunicación también se han hecho eco de esta idea, con, por ejemplo, “¿Por qué los bilingües son más inteligentes?” (La Vanguardia, 2012), “El bilingüísmo mejora la atención” (El País, 2007) o “El bilingüismo protege el cerebro” (El Mundo, 2014). Continúa leyendo en Rasgo Latente…
Producto interior bruto, interés por la ciencia y rendimiento científico
Una de las desgracias de ser español es que cuando se publican los resultados del informe PISA entras en un estado catatónico que te impide reaccionar a cualquier estimulación hasta que la siguiente jornada de liga te resetea y todo vuelve a la normalidad. Afortunadamente los habitantes de otros países son capaces de indagar y rebuscar en los datos de PISA sin que las lágrimas se lo impidan. Gracias a ellos, de vez en cuando descubrimos algunas pautas interesantes, como las que se perfilan en el estudio que acaban de publicar Elliot Tucker-Drob, Amanda Cheung y Daniel Brilley en Psychological Science.
El artículo se centra en la relación entre el interés por la ciencia y el rendimiento de los estudiantes en las pruebas de ciencia de los exámenes PISA. Lógicamente, los estudiantes a los que les interesa más la ciencia suelen puntuar más alto en estas pruebas. Lo interesante es que cómo de estrecha es esa relación depende de un número de factores. Si lo piensas bien, hay muchos obstáculos que pueden hacer que un estudiante con interés por la ciencia no llegue a ser bueno en ciencias. Tucker-Drob y colaboradores nos revelan algunos de ellos.
Uno de los resultados más interesantes es que el grado de relación entre interés por la ciencia y rendimiento científico depende del producto interior bruto (PIB) del país. En general, en los países más ricos, la relación entre interés y rendimiento es más fuerte. Se trata sólo de una correlación (aunque muy fuerte) que podría obedecer a varios motivos. La interpretación más sencilla es que los países más ricos proporcionan más oportunidades para que las personas con interés por ciencia desarrollen sus capacidades. En otras palabras, los países ricos facilitan que el talento se convierta en rendimiento. Aunque es interesante que también cabe la interpretación contraria: Tal vez los países donde las personas con interés por la ciencia pueden perseguir sus intereses acaben siendo más prósperos.
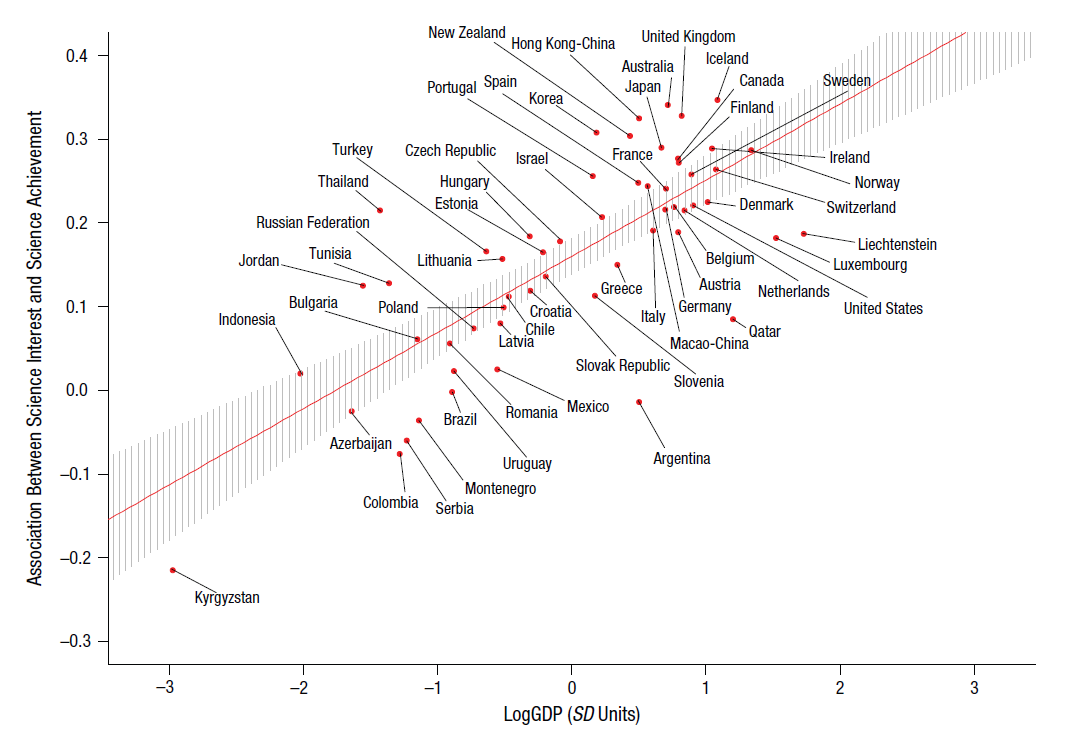 Reproduzco aquí la figura con los datos sobre la relación entre PIB y correlación interés-rendimiento. Cuidado al interpretar esta gráfica: Los países que están más arriba no son necesariamente los que obtienen mejor rendimiento en ciencias, sino aquellos donde la relación entre interés y rendimiento es más fuerte. Por una vez, agrada ver que España está ligeramente por encima del intervalo de confianza para esta regresión. Es decir, la relación entre interés y rendimiento es ligeramente mayor de lo que cabría predecir dado el PIB español. Italia, por ejemplo, tiene un PIB ligeramente superior, pero una correlación interés-rendimiento claramente inferior. Tal vez los datos más positivos sean los de Australia o Reino Unido, países que además de tener un PIB alto presentan una relación interés-rendimiento excepcionalmente alta. Se trata de países especialmente buenos a la hora de hacer que los alumnos más interesados consigan un buen dominio de las ciencias. Es curioso que algunos países muy prósperos, como Luxemburgo, presentan sin embargo correlaciones muy bajas.
Reproduzco aquí la figura con los datos sobre la relación entre PIB y correlación interés-rendimiento. Cuidado al interpretar esta gráfica: Los países que están más arriba no son necesariamente los que obtienen mejor rendimiento en ciencias, sino aquellos donde la relación entre interés y rendimiento es más fuerte. Por una vez, agrada ver que España está ligeramente por encima del intervalo de confianza para esta regresión. Es decir, la relación entre interés y rendimiento es ligeramente mayor de lo que cabría predecir dado el PIB español. Italia, por ejemplo, tiene un PIB ligeramente superior, pero una correlación interés-rendimiento claramente inferior. Tal vez los datos más positivos sean los de Australia o Reino Unido, países que además de tener un PIB alto presentan una relación interés-rendimiento excepcionalmente alta. Se trata de países especialmente buenos a la hora de hacer que los alumnos más interesados consigan un buen dominio de las ciencias. Es curioso que algunos países muy prósperos, como Luxemburgo, presentan sin embargo correlaciones muy bajas.
Otro dato interesante del estudio es que da pistas muy claras sobre cómo influye el estatus socio económico de la familia en la relación entre interés y rendimiento. Como cabría esperar, la ejecución de los niños está más relacionada con sus intereses en las familias de clase alta, que son las que tienen más recursos para hacer que los niños desarrollen sus intereses. Pero, y aquí viene lo bueno, esta relación está totalmente mediada por el estatus socio económico medio de las escuelas en las que estudian sus niños. Es decir, que importa más el estatus de la escuela que el estatus de la familia. O dicho de otra forma, si una familia tiene un niño con interés por la ciencia, merece la pena hacer el esfuerzo de enviar a ese niño a una escuela “por encima de sus posibilidades”.
El estudio arroja otros datos que dan que pensar, como que el interés por la ciencia correlaciona con el índice de democracia de un país, con su gasto en I+D, con el índice de justicia social y con el índice de coherencia social, aunque curiosamente no con el índice de desigualdad Gini ni con el acceso a la educación. Mastiquemos estos datos antes de que los resultados del siguiente informe nos quiten el apetito.
__________
Tucker-Drob, E. M., Cheung, A. K., & Briley, D. A. (in press). Gross domestic product, science interest, and science achievement: A person x nation interaction. Psychological Science.
Demasiado bonito para ser cierto
O al menos esa es la conclusión a la que llega Gregory Francis en su último y fulminante artículo sobre los sesgos de publicación en las revistas de psicología. El dedo acusador señala en esta ocasión a la prestigiosa Psychological Science. Aplicando un sencillo análisis estadístico a 44 artículos publicados entre 2009 y 2012, Francis ha encontrado que el número de resultados significativos es excesivamente alto en el 82% de ellos. La idea en la que se basa el análisis no puede ser más simple. Imagina que un artículo contiene cuatro experimentos y todos ellos obtienen resultados significativos. ¿Cuál es la probabilidad de que esto suceda? Es fácil calcularlo si uno conoce la potencia estadística de cada experimento. Si, por ejemplo, la potencia de los cuatro experimentos es de 0.75, 0.80, 0.90 y 0.85, entonces la probabilidad de que todos ellos arrojen resultados significativos es 0.75 x 0.80 x 0.90 x 0.85, es decir, 0.459. Se trata de un número razonable y plausible. Ahora bien, si la potencia de los experimentos hubiera sido, por ejemplo, 0.60, 0.70, 0.50 y 0.45, entonces la probabilidad de que todos ellos hubieran tenido resultados significativos habría sido 0.095. En general, cuando esta probabilidad es menor de 0.10 se considera que el número de resultados significativos es demasiado alto para lo que cabría esperar por azar y se entiende que debe haber tenido lugar un problema de publicación selectiva, p-hacking o simple fraude. O eso, o que la suerte está jugando una pasada muy mala. No es nada tranquilizador saber que la inmensa mayoría de los artículos publicados en Psychological Science sale mal parada en esta prueba. Menos aún si se tiene en cuenta que no es la primera vez que estudios como este ponen el prestigio de la revista en entredicho.
__________
Francis, G. (2014). The frequency of excess success for articles in Psychological Science. Psychonomic Bulletin & Review, 21, 1180-1187.
Ciegos ante la evidencia
Se han publicado decenas de artículos sobre la reticencia de los anti-vacunas o los negadores del cambio climático a aceptar la evidencia contraria a sus ideas. Casi todas las estrategias de intervención que se diseñan para luchar contra estas creencias fracasan una y otra vez. Las perspectivas de éxito resultan más desalentadoras, si cabe, cuando tenemos en cuenta que incluso las personas especializadas en cuestionar teorías y someterlas a prueba empírica son terriblemente reacias a cambiar sus ideas cuando los datos les llevan la contraria. Me refiero, cómo no, a los propios científicos.
O eso sugieren Clark Chinn y William Brewer en un sugerente artículo con el que acabo de toparme por casualidad. Según estudios previos que revisan en ese artículo, cuando los científicos se dan de bruces con un dato contrario a sus teorías, sólo ocasionalmente cambian sus creencias. En concreto, según la taxonomía de Chinn y Brewer, las ocho reacciones posibles ante la evidencia contraria son (a) ignorar los datos, (b) negar los datos, (c) excluir los datos, (d) suspender el juicio, (e) reinterpretar los datos, (f) aceptar los datos y hacer cambios periféricos en la teoría, y (g) aceptar los datos y cambiar las teorías.
Los autores utilizan un ejemplo real para ilustrar estas ocho reacciones. En la década de los 80 el premio Nobel Luis Álvarez y sus colaboradores propusieron que la extinción masiva del cretácico, en la que desaparecieron los dinosaurios, se había debido al impacto de un meteorito. El principal dato a favor de esta hipótesis era la alta concentración de iridio en el llamado límite KT, un estrato sedimentario que separaba el periodo cretácico de la era terciaria. El análisis de las citas que recibieron Álvarez y colaboradores durante los años siguientes a la publicación del artículo muestra que gran parte de la comunidad científica simplemente ignoró este descubrimiento (a). Durante algún tiempo incluso el propio equipo de Álvarez tuvo la sospecha de que los altos niveles de iridio en el límite KT podrían deberse a una contaminación de la muestra (b), lo que les obligó a tomar nuevas muestras. Algunos científicos sugirieron que los dinosaurios se habían extinguido 10.000 años antes del impacto del meteorito, con lo cual la capa de iridio no explicaba la extinción (c). Otros opinaban que la química del iridio no se conocía lo suficientemente bien como para poder extraer conclusiones (d). Tal vez algún día se podrían explicar esos altos niveles de iridio sin tener que asumir el impacto de un meteorito. Otro grupo de científicos reinterpretó los datos de Álvarez sugiriendo que el iridio del límite KT en realidad se habían filtrado de capas de sedimentos más recientes (e). También hubo quienes asumieron que el impacto del meteorito podría ser responsable de algunas de las extinciones del cretácico, pero no de todas ellas (f). Esto les permitía aceptar la evidencia encontrada por Álvarez pero sin renunciar a sus hipótesis previas sobre las causas de la extinción de los dinosaurios. Finalmente, algunos científicos renunciaron a sus hipótesis previas y aceptaron la nueva teoría sobre la extinción del cretácico (g).
No recuerdo si fue Thomas Kuhn o Max Planck quien dijo que la ciencia no evoluciona porque las teorías nuevas triunfen, sino porque quienes se oponen a ellas acaban muriéndose. Tal vez esa sea la novena y última reacción ante la evidencia contraria.
__________
Chinn, C. A., & Brewer, W. F. (1998). An empirical test of a taxonomy of responses to anomalous data in science. Journal of Research in Science Teaching, 35, 623-654.
El Gran Hermano experimenta contigo
Pocos experimentos de psicología alcanzan el impacto mediático que ha tenido el que acaban de publicar Kramer y colaboradores en la prestigiosa Proceedings of the National Academy of Sciences. En principio, el experimento no da para tanto. Simplificando mucho las cosas, su principal conclusión viene a ser que las emociones son contagiosas. Posiblemente se trata del efecto experimental más pequeño que jamás se ha publicado en una revista científica. (La d de Cohen de uno de los análisis es apenas 0.001.) El potencial incendiario del artículo no se debe a su contenido, sino a la metodología empleada. Los autores no se limitaron a llevar a un grupo de 50 participantes al laboratorio y observar su comportamiento, sino que manipularon las actualizaciones de Facebook de más de 600.000 internautas y observaron cómo cambiaba su comportamiento. Todo ello sin que los incautos participantes tuvieran la más mínima idea de que se estaba experimentando con ellos. En concreto, los investigadores limitaron el número de actualizaciones de carácter emocional positivo que aparecían en el feed de la mitad de los participantes y limitaron el número de actualizaciones negativas de la otra mitad. Como consecuencia de ello, el primer grupo de participantes empezó a publicar mensajes más negativos que el segundo.
La polémica se debe a que esta investigación no respeta las normas éticas de investigación que sirven de referente para hacer experimentos psicológicos o biomédicos. Uno de los requisitos básicos de cualquier estudio es que los participantes deben saber que sus datos están siendo observados y deben tener una información mínima sobre el estudio que les permita decidir libremente si quieren contribuir a él o no. También es requisito habitual que cualquier estudio tenga que ser previamente aprobado por un comité ético. El experimento de Kramer y colaboradores lógicamente no cumple con el primer criterio y no está claro sí llegó a ser aprobado o no por un comité ético ni en qué condiciones. Los autores se defienden en el propio artículo argumentando que el estudio no viola el acuerdo que los usuarios de Facebook firman cuando crean una cuenta de usuario.
Al otro lado de la polémica se sitúan los que sin llegar a aprobar esta conducta nos recuerdan que este tipo de estudios no son lo peor que se hace en las redes. El problema de la redes sociales no es que ocasionalmente se realice a través de ellas un estudio de interés científico sin que los participantes tengan noticia de ello. El verdadero problema es que las compañías realizan este tipo de estudios constantemente, con intereses puramente comerciales y sin publicar nunca los resultados de forma que sean accesibles a la ciudadanía. Tal vez sea un error atacar impasiblemente a los autores de un estudio que nos ha enseñado algo sobre la naturaleza humana a cambio de una pequeña manipulación de las actualizaciones de Facebook, mientras ignoramos el verdadero problema: La libertad con la que las redes sociales investigan sobre nosotros con intereses puramente comerciales y venden nuestra información al mejor postor.
__________
Kramer, A. D. I., Guillory, J. E., & Hancock, J. T. (2014). Experimental evidence of massive-scale emotional contagion through social networks. Proceedings of the National Academy of Sciences, 111, 8788-8790.
Las apariencias engañan, o por qué es mejor no cambiar de respuesta en un examen tipo test
Si eres aficionado a los blogs de ciencia, seguramente habrás leído una y mil veces que la correlación no implica causalidad. Lo que tal vez no hayas leído es que a veces una correlación puede llegar a ocultar una relación causal de signo contrario. Uno de los mecanismos que puede dar lugar a esta situación es lo que en estadística se conoce como paradoja de Simpson. Posiblemente el ejemplo más famoso de esta paradoja lo proporciona una demanda planteada a la Universidad de Berkeley por aplicar una política sexista de admisión de estudiantes. La demanda se basaba en que las estadísticas de la universidad mostraban que los hombres tenían más probabilidades de ser admitidos en la universidad. Sin embargo, cuando los responsables de la universidad desglosaron los datos por departamento, se observó que en realidad no había sesgos contra las mujeres en ningún departamento. Si acaso, la tendencia era la contraria: dentro de cualquier departamento, las mujeres tenían una pequeña ventaja sobre los hombres.
¿Cómo es posible que los datos de cada departamento mostraran una ventaja paras las mujeres y que los datos de la universidad en su conjunto mostraran una ventaja para los hombres? La explicación es que las mujeres echaban más solicitudes para los departamentos más complicados. Seguramente, Rafa Nadal ha perdido muchos más partidos de tenis que yo. Pero yo sólo he jugado contra mi hermano cuando tenía 7 años y Rafa Nadal ha jugado contra los mejores jugadores del mundo. Lo mismo sucedía con los hombres y las mujeres que solicitaban ser admitidos en Berkeley. Los datos mostraban que las mujeres tenían más interés por jugar en la primera liga.
Hace pocos días acabo de descubrir que esta paradoja podría tener la respuesta para uno de los problemas que más preocupan a la humanidad. Cuando estamos haciendo un examen tipo test, ¿debemos cambiar de respuesta si nos entran dudas? La sabiduría popular dicta que en caso de duda, es mejor ceñirse a nuestra respuesta original. Si el instinto nos dice que la respuesta correcta era la A, mejor no cambiar esa respuesta. Sin embargo, varios estudios científicos parecen mostrar que la intuición se equivoca: Tomados en su conjunto todos los datos, la probabilidad de acertar parece ser mayor para las personas que cambian de respuesta que para las que no.
Pues bien, según un estudio de van der Linden y colaboradores, esta aparente contradicción podría deberse a una paradoja de Simpson. Al parecer, es cierto que las personas que sacan mejores notas son también quienes más cambian de respuesta en los exámenes. A nivel grupal, esto produce una correlación entre cambiar de respuesta y sacar mejores notas. Pero esto no quiere decir que cambiar de respuesta mejore las notas. Si se mantiene constante la habilidad de los participantes, entonces la tendencia que se observa es la contraria: Si dos estudiantes son igual de buenos, entonces el que cambia menos de respuesta es el que saca mejores notas.
El ejemplo parece muy diferente al de la universidad de Berkeley. Sin embargo, se trata exactamente del mismo problema. Los datos parecen sugerir una correlación cuando se ignora un factor (los departamentos en el caso de la universidad y la habilidad de los estudiantes en el caso de los exámenes), pero la correlación es la contraria cuando ese factor se tiene en cuenta. Si el tema te interesa, estos y otros ejemplos los podrás encontrar en una magnífica introducción al tema que acaban de publicar Kievit y colaboradores en Frontiers in Psychology.
__________
Kievit, R. A., Frankenhuis, W. E., Waldorp, L. J., & Borsboom, D. (2013). Simpson’s paradox in psychological science: A practical guide. Frontiers in Psychology, 4, 513.
van der Linden, W. J., Jeon, M., & Ferrara, S. (2011). A paradox in the study of the benefits of test-item review. Journal of Educational Measurement, 48, 380-398.
¿Funciona el sistema de adjudicación de proyectos?
 Hay una larga tradición de investigación que muestra que los llamados expertos suelen ser absolutamente incapaces de hacer predicciones y pronósticos precisos. Si se te viene a la cabeza la figura de los economistas que predijeron la crisis después de que ya había pasado, sí, ese es un buen ejemplo. Según un sugerente artículo que acabo de encontrar en Science, tal vez podría decirse otro tanto de los científicos que cada año evaluamos los proyectos de investigación que se presentan a diversas instituciones para pedir financiación. Al parecer, la puntuación que los revisores damos a los proyectos correlaciona muy poco o nada con la productividad posterior de ese proyecto de investigación. En esta figura se muestran diversos indicadores de productividad de los proyectos financiados por los NIH norteamericanos entre 2001 y 2008. Como podrás comprobar, apenas hay diferencias entre los proyectos que obtuvieron las puntuaciones más altas y los que tuvieron peor nota. De hecho, tanto el número de publicaciones por proyecto como el número citas por millón de dólares gastado fueron ligeramente mayores para los proyectos con peor puntuación. Estos datos son doblemente sorprendentes porque los proyectos con peor nota son también los que reciben menos financiación y, por tanto, los que en igualdad de condiciones deberían ser menos productivos. Cabe dudar de si estos indicadores son los mejores para medir el impacto real de un proyecto de investigación. Pero en cualquier caso, estos datos son food for thought.
Hay una larga tradición de investigación que muestra que los llamados expertos suelen ser absolutamente incapaces de hacer predicciones y pronósticos precisos. Si se te viene a la cabeza la figura de los economistas que predijeron la crisis después de que ya había pasado, sí, ese es un buen ejemplo. Según un sugerente artículo que acabo de encontrar en Science, tal vez podría decirse otro tanto de los científicos que cada año evaluamos los proyectos de investigación que se presentan a diversas instituciones para pedir financiación. Al parecer, la puntuación que los revisores damos a los proyectos correlaciona muy poco o nada con la productividad posterior de ese proyecto de investigación. En esta figura se muestran diversos indicadores de productividad de los proyectos financiados por los NIH norteamericanos entre 2001 y 2008. Como podrás comprobar, apenas hay diferencias entre los proyectos que obtuvieron las puntuaciones más altas y los que tuvieron peor nota. De hecho, tanto el número de publicaciones por proyecto como el número citas por millón de dólares gastado fueron ligeramente mayores para los proyectos con peor puntuación. Estos datos son doblemente sorprendentes porque los proyectos con peor nota son también los que reciben menos financiación y, por tanto, los que en igualdad de condiciones deberían ser menos productivos. Cabe dudar de si estos indicadores son los mejores para medir el impacto real de un proyecto de investigación. Pero en cualquier caso, estos datos son food for thought.
La publicación selectiva perjudica seriamente la salud
Imagina que quiero convencerte de que soy un as jugando a los dardos. Para demostrártelo te enseño una grabación de video en la que tiro a diana diez veces y acierto en todas ellas. Impresionante, ¿verdad? Sólo hay una cosa que no termina de convencerte. Entre una y otra tirada hay un corte en la grabación. De repente se te ocurre pensar que a lo mejor he tirado los dardos 1000 veces y sólo te estoy enseñando las diez ocasiones en las que he acertado. Mi proeza ya no te impresiona tanto.
Por desgracia esta estratagema se utiliza recurrentemente en casi cualquier área de investigación científica, muchas veces sin que las propias personas que la practican se den cuenta de sus nefastas consecuencias. Es muy habitual que los investigadores realicen varios experimentos para poner a prueba sus hipótesis o que analicen de diferentes maneras los datos de cada experimento y que después sólo mencionen en el artículo aquellos experimentos o análisis que arrojaron los mejores resultados. Muchas veces son las propias revistas científicas las que piden directamente a los investigadores que quiten del artículo experimentos con resultados “feos”, poco concluyentes o redundantes. La consecuencia de todo ello es que buena parte de los resultados científicos que podemos encontrar en la literatura científica podrían ser falsos positivos, fruto del puro azar y nada más, como las diez dianas que conseguí a costa de hacer 1000 tiradas.
 Este problema ha alcanzado dimensiones preocupantes en las últimas décadas, con secuelas mucho más graves en unos ámbitos que en otros. El libro de Ben Goldacre Bad Pharma, traducido al castellano con el poco agraciado nombre de Mala Farma, es la mejor introducción a las repercusiones de esta política de investigación en el ámbito de la medicina y la farmacología. Cuando las grandes compañías farmacéuticas ponen a prueba la eficacia de sus medicinas, es frecuente que realicen múltiples ensayos clínicos o que analicen los efectos de estas sustancias sobre diferentes indicadores de salud. Cada vez que se realiza un nuevo ensayo clínico se está tirando un dardo a la diana. Si en un estudio no sólo se mide cómo afecta la medicina al corazón, sino también cómo afecta a los pulmones y al páncreas, entonces en ese estudio se han tirado tres dardos. A base de tirar más y más dardos, en algún momento los investigadores “encontrarán” algo. A lo mejor resulta que en el quinto ensayo clínico se observó que la sustancia S producía una reducción significativa de las nauseas matutinas en las embarazadas mayores de 37 años. Lo más probable es que la farmacéutica publique sólo este estudio, sin mencionar que se hicieron otros cuatro ensayos clínicos antes con resultados nulos o que en la muestra había también otros grupos de edad para los que la mejoría no fue significativa. El resultado de estas prácticas es que la literatura científica proporciona una imagen distorsionada de la eficacia de muchos medicamentos.
Este problema ha alcanzado dimensiones preocupantes en las últimas décadas, con secuelas mucho más graves en unos ámbitos que en otros. El libro de Ben Goldacre Bad Pharma, traducido al castellano con el poco agraciado nombre de Mala Farma, es la mejor introducción a las repercusiones de esta política de investigación en el ámbito de la medicina y la farmacología. Cuando las grandes compañías farmacéuticas ponen a prueba la eficacia de sus medicinas, es frecuente que realicen múltiples ensayos clínicos o que analicen los efectos de estas sustancias sobre diferentes indicadores de salud. Cada vez que se realiza un nuevo ensayo clínico se está tirando un dardo a la diana. Si en un estudio no sólo se mide cómo afecta la medicina al corazón, sino también cómo afecta a los pulmones y al páncreas, entonces en ese estudio se han tirado tres dardos. A base de tirar más y más dardos, en algún momento los investigadores “encontrarán” algo. A lo mejor resulta que en el quinto ensayo clínico se observó que la sustancia S producía una reducción significativa de las nauseas matutinas en las embarazadas mayores de 37 años. Lo más probable es que la farmacéutica publique sólo este estudio, sin mencionar que se hicieron otros cuatro ensayos clínicos antes con resultados nulos o que en la muestra había también otros grupos de edad para los que la mejoría no fue significativa. El resultado de estas prácticas es que la literatura científica proporciona una imagen distorsionada de la eficacia de muchos medicamentos.
Afortunadamente, el libro de Goldacre ha provocado tal revuelo que al menos en el Reino Unido se están empezando a tomar medidas para poner fin a esta situación. Si alguna vez te has preguntado si la divulgación científica sirve para algo, Bad Pharma es la prueba de que sí: a veces los divulgadores pueden cambiar el mundo para mejor. Una lectura imprescindible.
Qué es un Bayes factor, o dónde está el Diablo de Tasmania
Si tienes la suerte de llegar a mi edad, tarde o temprano la vida te confrontará con tres señales inequívocas de que te estás haciendo mayor. La primera es que la gente que sale en la tele es más joven que tú. La segunda, que los hijos de tus amigos se matriculan en la ESO. La tercera y más devastadora es que la estadística que se utiliza en los artículos científicos ya no se parece en nada a lo que estudiaste en la universidad. Todas hieren, pero esta última mata. Entre los nuevos fichajes de la estadística, brilla con luz propia el Bayes factor. En un magnífico manuscrito que Zoltan Dienes ha colgado en su página web he podido leer el mejor ejemplo que conozco de qué es y cómo calcularlo.
Imagina que tienes frente a ti una caja a la que, para seguirle el juego al autor, llamaremos la Caja de los Misterios de Zoltan. Dentro de ella puede haber o un Diablo de Tasmania o un gato. Si metes la mano en la caja y dentro está el Diablo de Tasmania, tienes un 90% de probabilidades de que te muerda un dedo y te lo arranque. Si lo que hay dentro de la caja es un gato, tus dedos tienen más probabilidades de salir bien parados. Pero aun así, el gatito se las trae. De modo que incluso en este caso, tienes un 10% de probabilidades de que te arranque un dedo. Sabiendo esto, metes tu mano en la Caja de los Misterios y cuando la sacas, descubres anonadado que te falta un dedo. Si necesitas hacerlo, detente un segundo para gritar “¡ay!” y maldecir a Félix Rodríguez de la Fuente. Si el bicho lo suelta, pon tu dedo cercenado en hielo, por si la cirugía del siglo XXI puede hacer algo.
Y ahora, dime. ¿Qué hay dentro de la caja? ¿Un Diablo de Tasmania o un gato? No puedes saberlo a ciencia cierta, pero este evento es más compatible con la idea de que se trata del pequeño Taz. ¿Cuánto más probable? Pues sea cual sea la creencia previa que tuvieras de que allí había un Diablo de Tasmania antes de meter la mano en la caja, ahora deberías multiplicar esa probabilidad por un factor 90% / 10%, es decir, 9 sobre 1. Este dato es precisamente el Bayes factor de la hipótesis HTASMANIA sobre la hipótesis HGATITO a la luz de tu doloroso experimento.
La idea general es que para saber si nuestros datos favorecen más a la Teoría A o a la Teoría B, lo que debemos hacer es calcular cómo de probables serían nuestros datos si la Teoría A fuera correcta y cómo de probables serían si al Teoría B fuera correcta. La división entre ambas probabilidades es precisamente el Bayes factor. En principio, la idea es sencilla, salvo porque no siempre es fácil o posible estimar cuál es la probabilidad de nuestros datos dadas las Teorías A o B. Pero hasta esto tiene solución. El texto de Zoltan es la mejor guía del viajero para adentrarse en estas tierras…
__________
