Se me ocurren muchas razones por las que merece la pena estudiar un nuevo idioma. Pero a juzgar por las conclusiones del artículo recién publicado por de Bruin, Treccani, y Della Sala (2015) en Psychological Science, tal vez deba tachar alguna de ellas de mi lista o al menos moverla más abajo. Durante los últimos años se ha hecho fuerte la idea de que el bilingüismo es una suerte de gimnasia mental que mejora diversas capacidades cognitivas, especialmente aquellas a las que se alude genéricamente con el nombre de control ejecutivo. Apenas puede uno abrir un volumen de cualquier revista de psicología sin encontrarse un artículo sobre el tema. Como no podría ser de otra forma, la idea se ha abierto camino rápidamente en la cultura popular y muy especialmente en el mundo de la educación. Los medios de comunicación también se han hecho eco de esta idea, con, por ejemplo, “¿Por qué los bilingües son más inteligentes?” (La Vanguardia, 2012), “El bilingüísmo mejora la atención” (El País, 2007) o “El bilingüismo protege el cerebro” (El Mundo, 2014). Continúa leyendo en Rasgo Latente…
Tag Archives: falso positivo
La publicación selectiva perjudica seriamente la salud
Imagina que quiero convencerte de que soy un as jugando a los dardos. Para demostrártelo te enseño una grabación de video en la que tiro a diana diez veces y acierto en todas ellas. Impresionante, ¿verdad? Sólo hay una cosa que no termina de convencerte. Entre una y otra tirada hay un corte en la grabación. De repente se te ocurre pensar que a lo mejor he tirado los dardos 1000 veces y sólo te estoy enseñando las diez ocasiones en las que he acertado. Mi proeza ya no te impresiona tanto.
Por desgracia esta estratagema se utiliza recurrentemente en casi cualquier área de investigación científica, muchas veces sin que las propias personas que la practican se den cuenta de sus nefastas consecuencias. Es muy habitual que los investigadores realicen varios experimentos para poner a prueba sus hipótesis o que analicen de diferentes maneras los datos de cada experimento y que después sólo mencionen en el artículo aquellos experimentos o análisis que arrojaron los mejores resultados. Muchas veces son las propias revistas científicas las que piden directamente a los investigadores que quiten del artículo experimentos con resultados “feos”, poco concluyentes o redundantes. La consecuencia de todo ello es que buena parte de los resultados científicos que podemos encontrar en la literatura científica podrían ser falsos positivos, fruto del puro azar y nada más, como las diez dianas que conseguí a costa de hacer 1000 tiradas.
 Este problema ha alcanzado dimensiones preocupantes en las últimas décadas, con secuelas mucho más graves en unos ámbitos que en otros. El libro de Ben Goldacre Bad Pharma, traducido al castellano con el poco agraciado nombre de Mala Farma, es la mejor introducción a las repercusiones de esta política de investigación en el ámbito de la medicina y la farmacología. Cuando las grandes compañías farmacéuticas ponen a prueba la eficacia de sus medicinas, es frecuente que realicen múltiples ensayos clínicos o que analicen los efectos de estas sustancias sobre diferentes indicadores de salud. Cada vez que se realiza un nuevo ensayo clínico se está tirando un dardo a la diana. Si en un estudio no sólo se mide cómo afecta la medicina al corazón, sino también cómo afecta a los pulmones y al páncreas, entonces en ese estudio se han tirado tres dardos. A base de tirar más y más dardos, en algún momento los investigadores “encontrarán” algo. A lo mejor resulta que en el quinto ensayo clínico se observó que la sustancia S producía una reducción significativa de las nauseas matutinas en las embarazadas mayores de 37 años. Lo más probable es que la farmacéutica publique sólo este estudio, sin mencionar que se hicieron otros cuatro ensayos clínicos antes con resultados nulos o que en la muestra había también otros grupos de edad para los que la mejoría no fue significativa. El resultado de estas prácticas es que la literatura científica proporciona una imagen distorsionada de la eficacia de muchos medicamentos.
Este problema ha alcanzado dimensiones preocupantes en las últimas décadas, con secuelas mucho más graves en unos ámbitos que en otros. El libro de Ben Goldacre Bad Pharma, traducido al castellano con el poco agraciado nombre de Mala Farma, es la mejor introducción a las repercusiones de esta política de investigación en el ámbito de la medicina y la farmacología. Cuando las grandes compañías farmacéuticas ponen a prueba la eficacia de sus medicinas, es frecuente que realicen múltiples ensayos clínicos o que analicen los efectos de estas sustancias sobre diferentes indicadores de salud. Cada vez que se realiza un nuevo ensayo clínico se está tirando un dardo a la diana. Si en un estudio no sólo se mide cómo afecta la medicina al corazón, sino también cómo afecta a los pulmones y al páncreas, entonces en ese estudio se han tirado tres dardos. A base de tirar más y más dardos, en algún momento los investigadores “encontrarán” algo. A lo mejor resulta que en el quinto ensayo clínico se observó que la sustancia S producía una reducción significativa de las nauseas matutinas en las embarazadas mayores de 37 años. Lo más probable es que la farmacéutica publique sólo este estudio, sin mencionar que se hicieron otros cuatro ensayos clínicos antes con resultados nulos o que en la muestra había también otros grupos de edad para los que la mejoría no fue significativa. El resultado de estas prácticas es que la literatura científica proporciona una imagen distorsionada de la eficacia de muchos medicamentos.
Afortunadamente, el libro de Goldacre ha provocado tal revuelo que al menos en el Reino Unido se están empezando a tomar medidas para poner fin a esta situación. Si alguna vez te has preguntado si la divulgación científica sirve para algo, Bad Pharma es la prueba de que sí: a veces los divulgadores pueden cambiar el mundo para mejor. Una lectura imprescindible.
p-curves, p-hacking, and p-sychology
 Pruebe a hacer el siguiente experimento. Haga click sobre el cuadro de texto de Google y comience a escribir “replication crisis”. Con su habitual don de gentes, el buscador enseguida se ofrecerá a auto-completar el término de búsqueda. En ningún caso leerá “replication crisis in physics” o “replication crisis in biology”. No. Google es más listo que eso. Quienes han buscado esos términos en el pasado por lo general han terminado escribiendo “replication crisis in psychology”. Y así nos lo arroja a la cara el simpático rastreador de la web.
Pruebe a hacer el siguiente experimento. Haga click sobre el cuadro de texto de Google y comience a escribir “replication crisis”. Con su habitual don de gentes, el buscador enseguida se ofrecerá a auto-completar el término de búsqueda. En ningún caso leerá “replication crisis in physics” o “replication crisis in biology”. No. Google es más listo que eso. Quienes han buscado esos términos en el pasado por lo general han terminado escribiendo “replication crisis in psychology”. Y así nos lo arroja a la cara el simpático rastreador de la web.
El mundo de la psicología se ha hecho un hueco en todas las portadas con sus recientes casos de fraude, sus misteriosas incursiones en el mundo de lo paranormal y, más recientemente, la imposibilidad de replicar uno o dos de sus más famosos y audaces experimentos. La otra parte de esta historia, menos sensacionalista pero más reveladora, es que la psicología también está en la primera línea de combate contra todo aquello que amenace a la integridad de la ciencia, dentro y fuera de sus fronteras. Algunas de las propuestas más ingeniosas para detectar y medir el impacto de las malas prácticas científicas se las debemos a la propia comunidad de investigadores de las ciencias del comportamiento. Una de mis favoritas tiene que ver con el estudio de la llamada curva de valores p.
En la estadística tradicional se procede de una forma un tanto retorcida. Para demostrar que un efecto existe lo que uno hace es asumir que no existe y luego ver cómo de rara sería la evidencia que hemos recogido si se parte de ese supuesto. El parámetro que mide cómo de extraño sería un dato bajo el supuesto de que un efecto no existe es lo que llamamos valor p. (En rigor, lo que mide el valor p es cómo de probable es encontrar un valor tan alejado o más de lo que cabría esperar bajo el supuesto de que la hipótesis nula es cierta.) Para lo que aquí nos interesa, basta con tener en cuenta que, por convención, se considera que uno ha observado un efecto significativo si el valor p de ese efecto es inferior a 0.05. Un valor tan pequeño quiere decir que es muy poco probable que el efecto se deba al puro azar. Que posiblemente hay un efecto real tras esos datos.
Imagine que queremos saber si una píldora reduce el dolor de cabeza. Para ello, hacemos el siguiente experimento. Le pedimos a un grupo de 50 personas que tome esa píldora todos los días y que apunte en una libreta cuándo le duele la cabeza. A otro grupo de personas le pedimos que haga exactamente lo mismo, pero sin que ellos lo sepan le damos un placebo. Después de un par de meses les pedimos que nos envíen las libretas y observamos que a los que han tomado la píldora les ha dolido la cabeza una media de 10 días. Sin embargo a los que han tomado el placebo les ha dolido la cabeza una media de 15 días. ¿Quiere esto decir que la píldora funciona? Bueno. Pues parece que sí. Pero la verdad es que este resultado podría deberse al puro azar. Para saber hasta qué punto se puede deber al azar o no, hacemos un análisis estadístico y nos dice que el valor p que obtenemos al comparar los grupos es, por ejemplo, 0.03. Como ese valor es inferior a 0.05, consideraríamos poco probable que la diferencia entre ambos grupos se deba al simple azar.
Aquí viene lo interesante. ¿Qué pasaría si la píldora realmente funciona y hacemos ese experimento muchas veces? Sin duda, aunque la píldora sea efectiva, el azar también influirá en los resultados. De modo que no siempre obtendremos los mismos datos. Y los análisis estadísticos no siempre arrojarán el mismo valor p. Unas veces será más alto y otras más bajo. Si el experimento se repitiera una y otra vez, la distribución de los valores p que obtendríamos debería parecerse a una curva exponencial en la que la mayor parte de los valores p serían muy pequeños y, sin embargo, habría relativamente menos experimentos que arrojaran valores p cercanos a 0.05. Esa gráfica, representando la distribución ideal de los valores p es lo que se denomina curva-p.
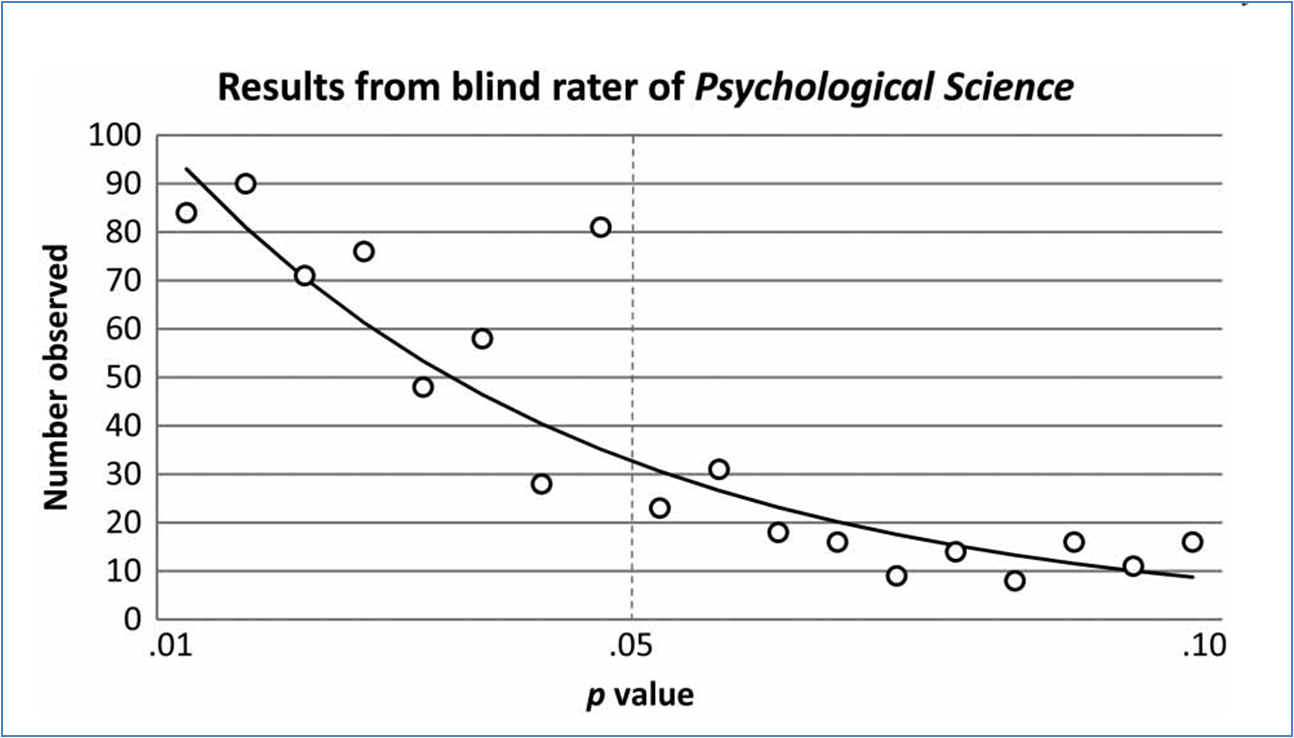 En condiciones normales, si uno coge los artículos que se publican en las revistas y registra sus valores p, deberían seguir una distribución similar a la que muestra esa curva. Pero, como ya puede imaginarse, no es eso lo que sucede. En el caso de algunas revistas la distribución real de valores p se aleja muy sustancialmente de la distribución ideal. En un estudio reciente, Masicampo y Lalande (2012) trazaron la curva de valores p de tres revistas extremadamente importantes en el ámbito de la psicología: Journal of Experimental Psychology: General, Journal of Personality and Social Psychology y Psychological Science. Los resultados indicaron que en los tres casos los valores p observados diferían significativamente de la distribución ideal. En concreto, en todas ellas había un número sospechosamente alto de valores inmediatamente inferiores a 0.05, que según la distribución ideal deberían ser los más infrecuentes. Como puede verse en la figura de la izquierda, en el caso de Psychological Science, la prevalencia de estos valores apenas significativos es realmente escalofriante.
En condiciones normales, si uno coge los artículos que se publican en las revistas y registra sus valores p, deberían seguir una distribución similar a la que muestra esa curva. Pero, como ya puede imaginarse, no es eso lo que sucede. En el caso de algunas revistas la distribución real de valores p se aleja muy sustancialmente de la distribución ideal. En un estudio reciente, Masicampo y Lalande (2012) trazaron la curva de valores p de tres revistas extremadamente importantes en el ámbito de la psicología: Journal of Experimental Psychology: General, Journal of Personality and Social Psychology y Psychological Science. Los resultados indicaron que en los tres casos los valores p observados diferían significativamente de la distribución ideal. En concreto, en todas ellas había un número sospechosamente alto de valores inmediatamente inferiores a 0.05, que según la distribución ideal deberían ser los más infrecuentes. Como puede verse en la figura de la izquierda, en el caso de Psychological Science, la prevalencia de estos valores apenas significativos es realmente escalofriante.
¿A qué se debe esta distribución anómala de valores p? A que algo huele a podrido en Dinamarca, claro. Estas distribuciones son probablemente el producto de muchas prácticas malsanas en el mundo de la investigación. Una buena parte de la responsabilidad la tienen las propias revistas y sus equipos editoriales. Si un estudio tiene un valor p de 0.049 se publica, pero si tiene un valor p de 0.051 no se publica. No es significativo. ¿Se hace esto porque hay alguna barrera infranqueable entre lo que es mayor o menor de 0.05? En absoluto. El umbral del 0.05 es una pura convención social. La mayor parte de las veces la diferencia entre un estudio con una p = 0.045 y otro con p = 0.055 es el puro azar y nada más. Pero para el investigador hay una diferencia fundamental entre ambos: obtener un 0.045 significa que su trabajo cae dentro de lo convencionalmente aceptado y por tanto se publicará. Y publicarlo supone que el trabajo que ha hecho será conocido y reconocido por la comunidad científica. Y cuando quiera presentarse a una plaza de profesor o pedir un proyecto de investigación su contribución a la ciencia será tenida en cuenta. Obtener un 0.055 significa que el trabajo cae dentro de lo convencionalmente inaceptable. Costará horrores publicarlo o, más probablemente, no se publicará. La comunidad científica no lo conocerá y difícilmente se le valorará al investigador por haber dedicado meses o años de su trabajo a ese estudio.
Lógicamente el investigador que obtienen un valor p feo no se mete las manos en los bolsillos y se queda esperando a tener más suerte con su siguiente proyecto de investigación. Es muy probable que empiece a juguetear con los datos para ver si hay algo que pueda explicar por qué sus resultados no son significativos. Por ejemplo, es posible que descubra que uno de sus pacientes en el grupo que tomaba la píldora tenía un cáncer terminal y que por eso le dolía la cabeza mucho más que al resto. Al meter a ese participante en los análisis se está inflando el dolor de cabeza medio que sienten los miembros del grupo experimental que toma la píldora. ¡Normal que las diferencias no sean del todo significativas! Lo más probable es que el investigador elimine a este participante de la muestra dando por sentado que es un caso anómalo que está contaminando los resultados. Parece algo tan de sentido común que cuesta ver dónde está el problema en hacerlo. Pues bien, el problema es que si ese participante anómalo hubiera resultado estar en el grupo control, el que tomaba el placebo, posiblemente el investigador ni se habría dado cuenta de que existía. Los resultados habrían parecido bonitos desde el principio: habría encontrado las diferencias significativas que esperaba.
En otras palabras, los datos feos tienen más probabilidad de mantenerse en el estudio cuando favorecen la hipótesis del investigador que cuando van en contra. Y lo que esto supone es que si el azar resulta ir en contra del investigador se hacen más intentos por corregirlo que si la suerte conspira para “ayudarle”. Todas estas prácticas de análisis de los datos que permiten al investigador inclinar la balanza a su favor es lo que en la literatura se conoce como p-hacking. Todas ellas suponen una importante amenaza para la integridad de los resultados científicos porque incrementan la probabilidad de que un resultado aparentemente significativo refleje en realidad un falso positivo.
¿Cómo solucionar el problema? Lo cierto es que afortunadamente pueden ensayarse varias soluciones. Pero eso ya es una historia para otra entrada en este blog…
__________
Masicampo, E. J., & Lalande, D. R. (2012). A peculiar prevalance of p values just below .05. Quarterly Journal of Experimental Psychology, 65, 2271-2279.
¿El ocaso del priming social?
Durante las dos últimas décadas, la psicología social ha sido un hervidero de incesantes descubrimientos, cada cual más sorprendente que el anterior. Juzguen ustedes mismos. Utilizar palabras relacionadas con la tercera edad nos hace movernos más despacio. Al ver el logo de Apple repentinamente nos volvemos más creativos. Rendimos más en una prueba de cultura general si antes hemos pensado en un catedrático universitario. Es más probable que nos prestemos voluntarios a participar en un estudio de psicología si justo antes hemos tocado un osito de peluche… Estos y otros experimentos similares vendrían a confirmar la omnipresencia de lo que se ha venido a llamar priming social: la fuerte influencia que, conforme a esta literatura, ejercen sobre nuestra conducta claves sutiles, por mecanismos que escapan a nuestro control consciente.
No es extraño que este tipo de resultados se haya abierto camino rápidamente en los manuales de psicología social y que actualmente se expliquen en cualquier curso universitario sobre la materia. Se trata de hallazgos interesantes e incluso perturbadores. Sin embargo, el adjetivo que mejor los define es “sorprendentes”. Primero, porque cuestionan nuestra concepción general sobre qué determina nuestra conducta y qué papel juega la voluntad consciente en ella. Y, segundo, porque aunque en el área de la psicología cognitiva también se han encontrado diversos ejemplos de priming, estos fenómenos casi siempre tienen un efecto pequeño, breve y sumamente efímero. Por ejemplo, resulta más fácil reconocer que la palabra “león” se refiere a un animal si antes hemos sido brevemente expuestos al nombre de otro animal. Sin embargo, pequeñas alteraciones del procedimiento experimental son suficientes para que esos efectos desaparezcan. A la luz de lo difícil que es observar el priming semántico o afectivo en el laboratorio, los experimentos que documentan que observar el logo de Apple o tocar un osito de peluche pueden influir en nuestra conducta social parecen sencillamente extraordinarios. Y ya se sabe lo que sucede con las afirmaciones extraordinarias: que requieren pruebas extraordinarias.
¿Demasiado bonito para ser cierto? Varios estudios realizados en los últimos meses así lo sugieren. La polémica sobre la credibilidad de estos resultados se desató cuando Doyen, Klein, Pichon y Cleeremans, de la Universidad Libre de Bruselas, publicaron en PLoS ONE un breve informe en el que describían dos experimentos en los que no habían conseguido replicar un famoso ejemplo de priming. Cuando apenas se ha calmado el revuelo causado por aquel artículo, PLoS ONE publica ahora un estudio similar de Shanks, Newell y colaboradores que echa otro jarro de agua fría a los investigadores del llamado priming social. En esta ocasión se han realizado nada menos que nueve experimentos en los que se intentaba replicar, sin éxito, otro estudio particularmente popular. El dudoso honor le ha correspondido esta vez al hallazgo de Dijksterhuis y van Knippenberg de que las personas puntúan más en una prueba de cultura general si antes han pasado un tiempo pensando en un profesor universitario que si han estado pensando en un grupo de hooligans.
A la publicación del artículo de Shanks y colaboradores le ha seguido una agria polémica, desgraciadamente similar a la que tuvo lugar en ocasiones anteriores. La reacción de Dijksterhuis ante estos resultados es ligeramente más diplomática, pero en lo sustancial se diferencia poco de la defensa que Bargh hizo de sus propios experimentos cuando fueron cuestionados por Doyen y colaboradores. También en esta ocasión, Dijksterhuis achaca la divergencia de resultados a “los extremadamente poco profesionales” experimentos de Shanks, a los que califica de “sub-standard”, y a la posible existencia de moderadores (aún desconocidos) que tal vez estén determinando si el efecto se observa o no. No han faltado tampoco en esta ocasión los habituales ataques a la política de revisión de PLoS ONE. Dijksterhuis ha señalado también que el efecto de priming de conductas inteligentes se ha replicado en numerosas ocasiones.
A mi juicio, una de las intervenciones más destacadas en este debate se la debemos a Gregory Francis, que recientemente ha publicado una nota en el foro de PLoS ONE cuestionando la integridad de las publicaciones originales sobre el priming de conductas inteligentes. Aplicando un sencillo análisis, Francis observa que la potencia estadística de los experimentos originales de Dijksterhuis es relativamente baja, en torno a un 50%. Esto supone que aunque el efecto existiera realmente, uno sólo esperaría observarlo realmente en aproximadamente la mitad de los experimentos realizados con esa potencia estadística. Sin embargo, en el artículo original de Dijksterhuis y van Knippenberg el efecto resultó ser significativo en los cuatro experimentos que allí se publicaban. Respondiendo a la pregunta de más arriba, estos datos son demasiado bonitos para ser ciertos. Esto no quiere decir que los autores hayan mentido sobre los resultados, pero sí invita a sospechar que o bien los experimentos en los que no se observaba el efecto no se publicaron o bien que en el análisis de los datos se utilizaron diversas estratagemas que sabemos que aumentan la posibilidad de obtener un falso positivo.
__________
Presintiendo el futuro… de la psicología
Conforme a la teoría de la gravedad de Newton, los planetas deberían recorrer una órbita elíptica alrededor del sol. Curiosamente, Urano no se mueve así. Su órbita es aproximadamente elíptica, sí, pero aquí y allí se desvía de forma caprichosa del que debería ser su curso normal. Cuando los astrónomos del siglo XIX lo descubrieron, supongo que alguno se llevaría las manos a la cabeza. Si hubieran estudiado el falsacionismo de Karl Popper, sin duda habrían llegado a la conclusión de que la teoría de Newton debía ser incorrecta. Pero ninguno de ellos dio este paso. En lugar de ello, asumieron que si Urano se comportaba de forma extraña y si la teoría de Newton era cierta, entonces debía haber cerca algún cuerpo desconocido de gran tamaño cuya masa influyera en la órbita de Urano. Así se descubrió Neptuno.
Esta historia tiene interesantísimas repercusiones para entender cómo evoluciona (y cómo debería evolucionar) la ciencia. Primero, nos enseña que hay que tener cuidado a la hora de interpretar los datos porque lo que parece consistente o inconsistente con una teoría a menudo admite otras interpretaciones. A veces creemos que unos datos nos dicen algo sobre una teoría (en este caso, la teoría de la gravitación universal de Newton), pero en realidad nos están diciendo algo sobre otra teoría (en este caso, la teoría obsoleta de que sólo había siete planetas en el sistema solar). Segundo, nos enseña que aunque haya que mantener la mente abierta ante los nuevos datos, a menudo también merece la pena persistir en el intento de mantener explicaciones sencillas incluso para los hechos que inicialmente parecen desafiarlas.
Pensando en aquellos astrónomos que no renunciaron a la teoría de Newton ante la primera adversidad, es sencillo entender por qué los psicólogos actuales también miran con escepticismo las recientes “demostraciones” de percepción extrasensorial que el pasado 2011 publicó Bem en un artículo que ha sembrado la polémica. El diseño de los experimentos es ciertamente audaz y confieso de antemano que despierta todas mis simpatías. En realidad, se trata nada menos que de nueve experimentos que utilizan técnicas completamente diferentes, pero cuyos resultados convergen en la conclusión de que en determinadas condiciones las personas pueden ser sensibles a eventos que aún no han sucedido.
Uno de mis experimentos favoritos se basa en una inversión temporal de un experimento típico de priming afectivo. En los experimentos normales de priming afectivo se observa que el tiempo que se tarda en juzgar si una palabra (como, por ejemplo, “flor”) es positiva es menor si justo antes se presenta muy brevemente otra palabra que también es positiva (como, por ejemplo, “vacaciones”). Nada sorprendente hasta aquí. Lo interesante de los experimentos de Bem es que obtiene efectos similares incluso cuando se invierte el orden en el que se presentan los estímulos. Es decir, que nos cuesta menos decir, por ejemplo, que la palabra “flor” es positiva, si después de nuestra respuesta se presenta muy brevemente la palabra “vacaciones”. Estos resultados son tan asombrosos que cuesta describirlos asépticamente sin utilizar signos de admiración. El resto de experimentos de Bem son muy diferentes, pero la característica común de todos ellos es que el comportamiento de los participantes se ve influido por estímulos que aún no ha visto en ese momento. De ahí el nombre del polémico artículo: Feeling the future. Impresionante, ¿verdad?
Amparándose en estos resultados muchos dirán que a la psicología científica no le queda más remedio que rendirse ante la evidencia de estas pruebas a favor de la percepción extrasensorial. Pero nada más lejos de la realidad. Los psicólogos siguen en sus trece y su escepticismo no se ha rebajado ni un ápice. Y creo que actúan con la misma sabiduría que los astrónomos que antes de abandonar la teoría de Newton hicieron todo lo posible por “estirarla” para explicar la anomalía en la órbita de Urano.
Tal vez la más sencilla interpretación de los datos de Bem es que, salvo que los intentos de replicación y los meta-análisis posteriores indiquen lo contrario, es extremadamente probable que se trate de falsos positivos. La estadística inferencial que utilizamos habitualmente en las ciencias del comportamiento se basa en la idea de que aceptamos una hipótesis cuando la probabilidad de que las pruebas a su favor se deban al azar es inferior al 5%. Esto quiere decir que aunque diseñemos nuestros experimentos muy bien, en un 5% de las ocasiones (es decir, una de cada veinte veces) aceptaremos como válida una hipótesis falsa que parece verdadera por puro azar. Parece que este riesgo es pequeño, pero significa que si hacemos muchos experimentos a favor de nuestra hipótesis, aunque sea falsa, uno de cada veinte experimentos parecerá darnos la razón. Nosotros sabemos que nueve de los experimentos de Bem dan apoyo a la idea de que existe la percepción extrasensorial. Pero no sabemos si se trata de los únicos nueve experimentos que Bem ha realizado o si se trata de nueve experimentos elegidos de un conjunto más amplio (en el cual no todos los experimentos apoyaban esa hipótesis).
Incluso para el investigador más honesto (y no dudo de que Bem lo sea) es fácil caer en estos errores sin darse cuenta. Diseñamos un estudio piloto para explorar un nuevo fenómeno y si los primeros cinco datos que obtenemos parecen ambiguos, en lugar de terminar el experimento, hacemos un pequeño cambio en el experimento y vemos que pasa. Si los resultados no son más favorables ahora, tomamos esta segunda prueba como buena y la primea como mala. Por el contrario, si el segundo experimento también parece arrojar resultados ambiguos o abiertamente contrarios, es posible que no obstante realicemos un tercer experimento con pequeñas modificaciones para ver qué pasa. Y así sucesivamente. Al final, tendremos unos cuantos experimentos “piloto” fallidos o ambiguos y unos pocos experimentos que tienen resultados más favorables a nuestra hipótesis y que, como “padres de la criatura”, no podemos evitar tomar por buenos. Y, por supuesto, la publicación selectiva de resultados es sólo una de las malas (pero habituales) prácticas que puede llevarnos a caer en falsos positivos. (Véanse mis entradas previas sobre el tema aquí y aquí.)
Para evitar caer en falsos positivos, es fundamental que antes de darse por universalmente aceptado, un fenómeno sea replicado varias veces y, si es posible, por investigadores diferentes. Si el efecto existe realmente, deberían poder replicarse los resultados sin dificultad. Si ha sido un falso positivo, empezarán a observarse resultados negativos. El problema es que realizar estas réplicas consume mucho tiempo. Tiempo que los investigadores profesionales a menudo no tienen, porque sus carreras académicas dependen más de descubrir cosas nuevas que de comprobar si se replican resultados que han obtenido otros. (Hay que recordar que las principales revistas de psicología casi nunca aceptan la publicación de un trabajo que se limite a replicar a otro.)
Si en el caso de la órbita de Urano, la contradicción entre la teoría y los datos se solventó al descubrir Neptuno, ¿cómo se resolverá la contradicción entre los datos de Bem y las convicciones de los científicos de que el futuro no influye en el presente? Por lo pronto, los experimentos que han realizado otros psicólogos no han replicado los resultados de Bem (Ritchie, Wiseman, & French, 2012); así que parece poco probable que tengamos que reescribir los fundamentos de nuestra ciencia. Sin embargo, el caso de los experimentos de Bem es una ocasión excelente para replantearnos la forma en que realizamos investigación en psicología y en las ciencias de la salud en general. Son varios los artículos teóricos que han aprovechado esta ocasión para hacer esta misma lectura. De entre ellos recomiendo al menos dos. El de Wagenmakers, Wetzels, Borsboom y van der Maas (2011), publicado en el mismo volumen que el artículo original de Bem, es un alegato contra la utilización de análisis estadísticos laxos para poner a prueba hipótesis controvertidas. El otro, publicado por LeBel y Peters (2011) en el Review of General Psychology, nos invita entre otras cosas a hacer réplicas exactas de los experimentos más importantes en lugar de las habituales réplicas conceptuales (en las que se “repite” un experimento, pero variando detalles del procedimiento para ver si los resultados se mantienen a pesar de los cambios). Proporciona también un excelente análisis de por qué con frecuencia no prestamos toda la atención que se merecen a los intentos fallidos de réplicas. Lamentablemente no tengo espacio aquí para explicar con detalle ambos artículos, pero son dos excelentes muestras de cómo la verdadera ciencia aprovecha cualquier duda y debate para salir fortalecida.
__________
La ciencia de bocado engorda más
Una nueva moda ha invadido la ciencia durante los últimos cinco años: el brief report. A la costumbre tradicional de agrupar en cada artículo varios experimentos con evidencia convergente sobre un fenómeno le ha sucedido una tendencia cada vez más acusada a publicar artículos cortos en los que la introducción teórica se reduce al mínimo indispensable, el número de experimentos se limita a uno o dos y las discusiones teóricas van directamente al grano, sin florituras. Las ventajas de este tipo de publicaciones son muchas; sobre todo que los revisores pueden evaluar el artículo más rápidamente, los artículos aceptados ven la luz antes y la comunidad científica no necesita perder mucho tiempo para leer la versión definitiva. Algunos investigadores también han estimado que aunque el índice de impacto de las revistas que publican estos artículos breves tiende a ser más bajo, el índice de impacto por página es sin embargo mayor, lo que sugiere que en realidad estos artículos funcionan mejor a la hora de transmitir las ideas a la audiencia y estimular nueva investigación. Sin embargo, esta moda no está exenta de peligros. En un artículo (paradójicamente breve) que acaba de ver la luz en Perspectives on Psychological Science, Bertamini y Munafò reflexionan sobre el posible impacto negativo de los brief reports.
En primer lugar, muchas de las ventajas de estos artículos son cuestionables. Por ejemplo, el mayor índice de impacto por página que tienen estas revistas podría ser una consecuencia de que los autores dividan en varios artículos trabajos que en realidad deberían publicarse en un único artículo. Si esos diversos artículos se citan siempre juntos, eso puede producir la impresión de que ese trabajo tiene más impacto: una única idea genera varias citas. Pero sería una mera ilusión de impacto. Además, aunque los artículos breves conllevan menos trabajo para los editores y los revisores de las revistas científicas, a nivel global se multiplica el número de artículos que los investigadores envían a publicar, con lo cual en realidad se está aumentando el tiempo que se dedica colectivamente a estas tareas, aunque se esté reduciendo el trabajo por artículo individual.
En segundo lugar, este tipo de artículos breves tiene más probabilidades de arrojar falsos positivos. Por una parte, como se dan datos únicamente de uno o dos experimentos, no queda claro que los resultados que ahí aparezcan sean fácilmente replicables. Bertamini y Munafò observan que los brief reports no sólo incluyen menos experimentos, sino que además estos experimentos suelen tener muestras más pequeñas, lo que de nuevo favorece que aparezcan falsos positivos asociados a la falta de poder estadístico.
Las revistas pueden tener interés a corto plazo en favorecer estos informes breves de experimentos realizados con muestras pequeñas. Sus índices de impacto suben con el número de citas. Así que les interesa publicar artículos fáciles de leer y que generen polémica, independientemente de que se produzca porque otros autores repliquen los resultados o porque no consigan hacerlo. No en vano, los autores de este estudio observan que existe una correlación entre el índice de impacto de una revista y el grado en el que sus artículos exageran el tamaño real de los efectos que estudian. En otras palabras, las revistas pueden tener interés en vender “aire” porque aunque eso no haga progresar la ciencia, sí que genera citas y discusión.
La solución a estos problemas pasa por medir el impacto de las revistas no sólo por el número de citas que obtienen, sino también por otros criterios de calidad como la replicabilidad de sus resultados y los sesgos de publicación que puedan observarse entre sus artículos. También abogan por sustituir el actual énfasis en la cantidad de publicaciones por una mejor valoración de su calidad. En este sentido, destacan la política del Research Excellence Framwork del Reino Unido que desde hace unos años valora la producción científica de los departamentos y de los candidatos a diferentes puestos teniendo en cuenta únicamente las cuatro mejores publicaciones de los investigadores, de modo que se les incentiva para primar la calidad sobre la cantidad.
__________
Antidoping para la ciencia
Imagina que estás realizando tu tesis doctoral y que, tras dos meses de arduo trabajo, acabas de recoger todos los datos de un experimento en el que pones a prueba, qué sé yo, si administrar sustancia X afecta al estado emocional de un grupo de pacientes con estrés post-traumático. Metes todos tus datos en un programa informático, ejecutas los comandos necesarios para comparar los datos del grupo experimental con los del grupo de control y, tras un redoble de tambor que suena sólo en tu mente, descubres de la significación estadística de la diferencia es… p = 0.057.
Lo que iba a ser un día feliz se ha venido abajo. Según lo que te han enseñado en clase de estadística, no has descubierto nada de nada. No hay razones para pensar que la sustancia influye en el estado anímico, porque para poder sospechar que existe esa relación, el valor de esa p debería ser menor de 0.05. Estuviste cerca, pero fallaste. ¿O tal vez no? ¿Y si resulta que estás en lo cierto, que esa sustancia tiene el efecto que tú crees pero a tu experimento le falta lo que llamamos “poder estadístico”? ¿Y si simplemente necesitas recoger más datos para confirmar tus sospechas?
Los científicos nos enfrentamos muy habitualmente a situaciones como estas y casi siempre tomamos la misma decisión: Ampliar nuestra muestra para ver hacia dónde se mueve esa p. Parece algo inocente. Al fin y al cabo, ¿cómo puede conducirnos a engaño basar nuestras conclusiones en más datos? Sin embargo, actuar así tiene sus riesgos. En principio, siguiendo rigurosamente los cánones de la metodología científica, antes de hacer un experimento deberíamos decidir cuántas observaciones vamos a realizar y después deberíamos creernos lo que salga de esa muestra. Hacer lo contrario, analizar los datos cuando tenemos parte de la muestra y ampliarla más o menos según lo que nos vayan diciendo esos análisis, es peligroso porque puede arrojar falsos positivos: Supone incrementar el riesgo de que esa p sea menor que 0.05 se deba al simple azar y no a que hayamos descubierto una diferencia realmente significativa. Pero el proceso no está libre de ambigüedades porque, para empezar, ¿cómo sabemos a priori cuál es el tamaño ideal para nuestra muestra?
En un interesantísimo artículo que acaba de publicarse en Psychological Science, Joseph Simmons, Leif Nelson y Uri Simonsohn, nos muestran hasta qué punto pueden ser dañinas estas prácticas y otras similares, tales como omitir información sobre algunas variables dependientes en favor de otras, decidir si realizar un análisis teniendo o sin tener en cuenta una covariable, o informar sólo de los grupos que mejor se ajustan a los resultados deseados. Mediante una simulación informática muestran que si los investigadores se permiten recurrir libremente a estas estrategias, las posibilidades de que los datos lleguen a reflejar relaciones inexistentes crecen de una forma vertiginosa. De hecho, llegan a estimar que recurriendo a la vez a todas ellas, la probabilidad de que una diferencia significativa refleje un falso positivo (que normalmente debería ser del 5%; eso es lo que significa precisamente la p de más arriba) puede llegar al 60.7%.
Por si estas simulaciones no fueran suficiente, los autores recurren a un argumento mucho más didáctico. Realizan dos experimentos en los que violando estas reglas demuestran que la gente se hace más joven (no que se sienta más joven, ¡sino que es más joven literalmente!) tras escuchar “When I’m sixty-four” de los Beatles que tras escuchar “Kalimba” una canción instrumental incluida en el Windows 7. En otras palabras, aunque utilicemos controles experimentales rigurosos y análisis estadísticos robustos y adecuados, permitirnos la libertad de ampliar muestra a nuestro antojo, seleccionar los grupos o las variables dependientes más favorables o realizar los análisis que nos parezcan mejores a posteriori, puede permitirnos demostrar cualquier cosa y su contraria. Esta conclusión viene a coincidir con la que hace unos años expresaba Ioannidis en un popular artículo cuyo nombre lo decía todo: Why most published research findings are false.
El artículo de Simmons y colaboradores concluye con una serie de recomendaciones a los investigadores y a los revisores de revistas científicas para reducir el peligro de obtener falsos positivos. Lo que sugieren, básicamente, se reduce a pedir a los autores que sean más transparentes con las medidas que realizan, con el número de grupos que utilizaron, con el criterio que siguieron a la hora de decidir el tamaño muestral y con los resultados que tienen cuando los análisis se realizan de diferentes maneras. Los revisores, lógicamente, tienen que asegurarse de que se cumpla con estos estándares. Pero también les lanza una recomendación importante: deberían ser más tolerantes con las imperfecciones de los resultados. Al fin y al cabo, si el experimento de más arriba se hubiera podido publicar con esa p = 0.057, la historia habría terminado ahí.
__________
Ioannidis, J. P. A. (2005). Why most published research findings are false. PLoS Medicine, 2, e124.
