Las técnicas estadísticas que utilizamos habitualmente en los experimentos de psicología están pensadas para evitar caer en el error de ver una pauta donde sólo hay ruido y azar. Precisamente por eso, estas técnicas no deben utilizarse cuando lo que queremos hacer es demostrar que los datos se deben al azar. A pesar de ello, hay grandes áreas de investigación donde se cae en este error de forma rutinaria. Un ejemplo fascinante es la investigación sobre aprendizaje implícito (o inconsciente). Según un meta-análisis reciente, buena parte de lo que creemos saber sobre el aprendizaje inconsciente podría estar sesgado por este sencillo error. Continúa leyendo en Ciencia Cognitiva…
Tag Archives: estadística
Demasiado bonito para ser cierto
O al menos esa es la conclusión a la que llega Gregory Francis en su último y fulminante artículo sobre los sesgos de publicación en las revistas de psicología. El dedo acusador señala en esta ocasión a la prestigiosa Psychological Science. Aplicando un sencillo análisis estadístico a 44 artículos publicados entre 2009 y 2012, Francis ha encontrado que el número de resultados significativos es excesivamente alto en el 82% de ellos. La idea en la que se basa el análisis no puede ser más simple. Imagina que un artículo contiene cuatro experimentos y todos ellos obtienen resultados significativos. ¿Cuál es la probabilidad de que esto suceda? Es fácil calcularlo si uno conoce la potencia estadística de cada experimento. Si, por ejemplo, la potencia de los cuatro experimentos es de 0.75, 0.80, 0.90 y 0.85, entonces la probabilidad de que todos ellos arrojen resultados significativos es 0.75 x 0.80 x 0.90 x 0.85, es decir, 0.459. Se trata de un número razonable y plausible. Ahora bien, si la potencia de los experimentos hubiera sido, por ejemplo, 0.60, 0.70, 0.50 y 0.45, entonces la probabilidad de que todos ellos hubieran tenido resultados significativos habría sido 0.095. En general, cuando esta probabilidad es menor de 0.10 se considera que el número de resultados significativos es demasiado alto para lo que cabría esperar por azar y se entiende que debe haber tenido lugar un problema de publicación selectiva, p-hacking o simple fraude. O eso, o que la suerte está jugando una pasada muy mala. No es nada tranquilizador saber que la inmensa mayoría de los artículos publicados en Psychological Science sale mal parada en esta prueba. Menos aún si se tiene en cuenta que no es la primera vez que estudios como este ponen el prestigio de la revista en entredicho.
__________
Francis, G. (2014). The frequency of excess success for articles in Psychological Science. Psychonomic Bulletin & Review, 21, 1180-1187.
Qué es un Bayes factor, o dónde está el Diablo de Tasmania
Si tienes la suerte de llegar a mi edad, tarde o temprano la vida te confrontará con tres señales inequívocas de que te estás haciendo mayor. La primera es que la gente que sale en la tele es más joven que tú. La segunda, que los hijos de tus amigos se matriculan en la ESO. La tercera y más devastadora es que la estadística que se utiliza en los artículos científicos ya no se parece en nada a lo que estudiaste en la universidad. Todas hieren, pero esta última mata. Entre los nuevos fichajes de la estadística, brilla con luz propia el Bayes factor. En un magnífico manuscrito que Zoltan Dienes ha colgado en su página web he podido leer el mejor ejemplo que conozco de qué es y cómo calcularlo.
Imagina que tienes frente a ti una caja a la que, para seguirle el juego al autor, llamaremos la Caja de los Misterios de Zoltan. Dentro de ella puede haber o un Diablo de Tasmania o un gato. Si metes la mano en la caja y dentro está el Diablo de Tasmania, tienes un 90% de probabilidades de que te muerda un dedo y te lo arranque. Si lo que hay dentro de la caja es un gato, tus dedos tienen más probabilidades de salir bien parados. Pero aun así, el gatito se las trae. De modo que incluso en este caso, tienes un 10% de probabilidades de que te arranque un dedo. Sabiendo esto, metes tu mano en la Caja de los Misterios y cuando la sacas, descubres anonadado que te falta un dedo. Si necesitas hacerlo, detente un segundo para gritar “¡ay!” y maldecir a Félix Rodríguez de la Fuente. Si el bicho lo suelta, pon tu dedo cercenado en hielo, por si la cirugía del siglo XXI puede hacer algo.
Y ahora, dime. ¿Qué hay dentro de la caja? ¿Un Diablo de Tasmania o un gato? No puedes saberlo a ciencia cierta, pero este evento es más compatible con la idea de que se trata del pequeño Taz. ¿Cuánto más probable? Pues sea cual sea la creencia previa que tuvieras de que allí había un Diablo de Tasmania antes de meter la mano en la caja, ahora deberías multiplicar esa probabilidad por un factor 90% / 10%, es decir, 9 sobre 1. Este dato es precisamente el Bayes factor de la hipótesis HTASMANIA sobre la hipótesis HGATITO a la luz de tu doloroso experimento.
La idea general es que para saber si nuestros datos favorecen más a la Teoría A o a la Teoría B, lo que debemos hacer es calcular cómo de probables serían nuestros datos si la Teoría A fuera correcta y cómo de probables serían si al Teoría B fuera correcta. La división entre ambas probabilidades es precisamente el Bayes factor. En principio, la idea es sencilla, salvo porque no siempre es fácil o posible estimar cuál es la probabilidad de nuestros datos dadas las Teorías A o B. Pero hasta esto tiene solución. El texto de Zoltan es la mejor guía del viajero para adentrarse en estas tierras…
__________
Ruidos, señales y overfitting
 Aunque llevaba meses deseando hacerme con un ejemplar del último libro de Nate Silver, The signal and the noise: The art and science of prediction, confieso que el primer contacto no me pareció muy alentador. Nada más mirar la foto del autor en la contraportada tuve la sensación de que alguien me susurraba al oído “perrea, perrea”. La cosa no mejoró cuando leí los primeros capítulos y descubrí que los temas que Silver había elegido para presentar su tesis eran de esos que despiertan un interés inversamente proporcional a la distancia que te separa de Oklahoma. El relato transcurre entre ligas de béisbol, elecciones a la presidencia de EE.UU., partidas de póker y otras pamplinas que posiblemente hagan la delicia del norteamericano medio, pero carecen de adeptos a este lado del charco.
Aunque llevaba meses deseando hacerme con un ejemplar del último libro de Nate Silver, The signal and the noise: The art and science of prediction, confieso que el primer contacto no me pareció muy alentador. Nada más mirar la foto del autor en la contraportada tuve la sensación de que alguien me susurraba al oído “perrea, perrea”. La cosa no mejoró cuando leí los primeros capítulos y descubrí que los temas que Silver había elegido para presentar su tesis eran de esos que despiertan un interés inversamente proporcional a la distancia que te separa de Oklahoma. El relato transcurre entre ligas de béisbol, elecciones a la presidencia de EE.UU., partidas de póker y otras pamplinas que posiblemente hagan la delicia del norteamericano medio, pero carecen de adeptos a este lado del charco.
Y sin embargo, el libro es una buenísima introducción a los problemas a los que se enfrenta cualquiera que quiera entender un sistema dinámico complejo y predecir su evolución. Entre otras cosas, el libro contiene la mejor explicación que conozco del concepto de overfitting. Si el lector no se ha encontrado nunca con esta palabreja, posiblemente creerá que el overfitting es el trastorno psiquiátrico que sufren las personas que van todos los días al gimnasio. Pero en realidad se trata de un concepto estadístico relacionado con cómo se ajusta un modelo a la realidad que pretende explicar y predecir. En principio, si uno desarrolla una teoría para explicar algo, cabría pensar que cuanto más se ajuste la teoría a los hechos, tanto mejor será la teoría. Pero en realidad puede suceder lo contrario: que una teoría sea mala precisamente porque se ajusta demasiado a los datos. Es entonces cuando decimos que el modelo tiene overfitting o sobreajuste. Veámoslo con el ejemplo que nos da el propio Nate Silver.
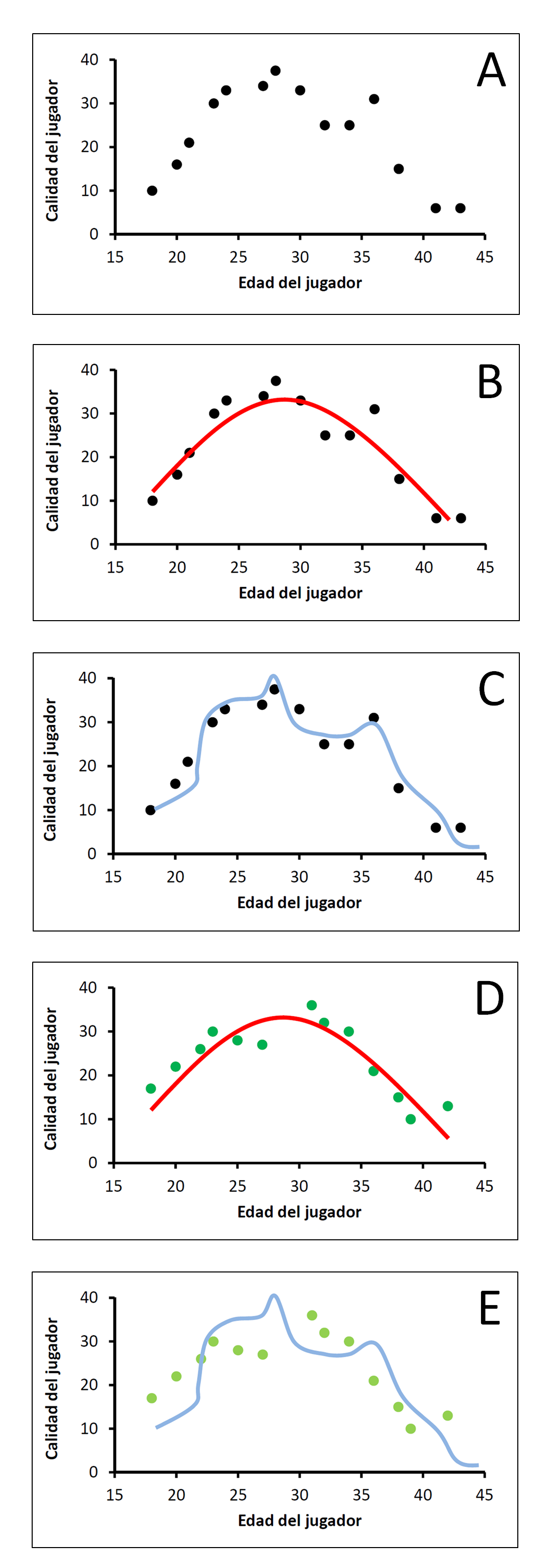 Imagina que queremos saber cómo evoluciona la calidad de un jugador de béisbol a medida que se va haciendo mayor. Lo primero que tenemos que hacer es recoger datos. Tras hacer algunas mediciones aquí y allá conseguimos la información que tenemos en el panel A. La forma más sencilla de explicar este patrón de resultados es asumir que la calidad de un jugador se incrementa progresivamente a medida que se va haciendo mayor hasta que llega un momento en el que la tendencia comienza a invertirse. Este modelo, al que llamaré Modelo 1, es el que aparece en el panel B. Como puede verse, el modelo no se ajusta a los datos a la perfección. De lo contrario todos los circulitos deberían estar exactamente en la línea. Sin embargo, el ajuste del modelo es aceptable. ¿Es posible diseñar un modelo con un ajuste todavía mejor? Por supuesto, el panel C muestra una línea alternativa que pasa mucho más cerca de todos los puntos. Llamemos a esta línea Modelo 2. La distancia media entre la línea y cada observación es menor para el Modelo 2 que para el Modelo 1. Ahora bien, ¿quiere eso decir que es un modelo mejor?
Imagina que queremos saber cómo evoluciona la calidad de un jugador de béisbol a medida que se va haciendo mayor. Lo primero que tenemos que hacer es recoger datos. Tras hacer algunas mediciones aquí y allá conseguimos la información que tenemos en el panel A. La forma más sencilla de explicar este patrón de resultados es asumir que la calidad de un jugador se incrementa progresivamente a medida que se va haciendo mayor hasta que llega un momento en el que la tendencia comienza a invertirse. Este modelo, al que llamaré Modelo 1, es el que aparece en el panel B. Como puede verse, el modelo no se ajusta a los datos a la perfección. De lo contrario todos los circulitos deberían estar exactamente en la línea. Sin embargo, el ajuste del modelo es aceptable. ¿Es posible diseñar un modelo con un ajuste todavía mejor? Por supuesto, el panel C muestra una línea alternativa que pasa mucho más cerca de todos los puntos. Llamemos a esta línea Modelo 2. La distancia media entre la línea y cada observación es menor para el Modelo 2 que para el Modelo 1. Ahora bien, ¿quiere eso decir que es un modelo mejor?
Tal vez no. El objetivo de una buena teoría no es sólo ajustarse bien a la evidencia que ya tenemos, sino también predecir los datos que podríamos observar en el futuro. Imagina que recabamos información sobre otros jugadores y que los circulitos verdes del panel D representan los resultados de estas nuevas observaciones. Estos datos siguen estando relativamente cerca de lo que predecía el Modelo 1. Sin embargo, el Modelo 2, que originalmente parecía ajustarse muy bien a los datos, ya no coincide de forma tan elegante con las nuevas observaciones.
En la terminología de Nate Silver, lo que le pasa al Modelo 2 es que no sólo trata de explicar la señal de la relación entre la edad y la calidad de un jugador, sino también el ruido aleatorio que inevitablemente contamina los datos. El modelo está tan ajustado a las observaciones que explica incluso lo que no debería explicar: la varianza que se debe al puro azar.
Las neurociencias y el gatillazo estadístico
Los estudios de neurociencias son al clásico experimento de psicología lo que un crucero por las Bahamas a un viaje en interrail. Extremadamente caros. Pagar a los participantes por desplazarse hasta el laboratorio, pagar por el uso del fMRI, pasar cientos de horas analizando datos… Todo ello supone dinero, dinero y más dinero. En muchos laboratorios donde se hacen experimentos con ERPs hasta contratan un servicio de peluquería para adecentar al pobre participante, que termina el experimento con la cabeza llena de gel. Una consecuencia directa del elevado coste es que los investigadores, lógicamente, intentan ahorra dinero por todas partes. Si el experimento puede hacerse con diez personas, mejor que con treinta. ¿Verdad? Continúa leyendo en Psicoteca…
Antidoping para la ciencia
Imagina que estás realizando tu tesis doctoral y que, tras dos meses de arduo trabajo, acabas de recoger todos los datos de un experimento en el que pones a prueba, qué sé yo, si administrar sustancia X afecta al estado emocional de un grupo de pacientes con estrés post-traumático. Metes todos tus datos en un programa informático, ejecutas los comandos necesarios para comparar los datos del grupo experimental con los del grupo de control y, tras un redoble de tambor que suena sólo en tu mente, descubres de la significación estadística de la diferencia es… p = 0.057.
Lo que iba a ser un día feliz se ha venido abajo. Según lo que te han enseñado en clase de estadística, no has descubierto nada de nada. No hay razones para pensar que la sustancia influye en el estado anímico, porque para poder sospechar que existe esa relación, el valor de esa p debería ser menor de 0.05. Estuviste cerca, pero fallaste. ¿O tal vez no? ¿Y si resulta que estás en lo cierto, que esa sustancia tiene el efecto que tú crees pero a tu experimento le falta lo que llamamos “poder estadístico”? ¿Y si simplemente necesitas recoger más datos para confirmar tus sospechas?
Los científicos nos enfrentamos muy habitualmente a situaciones como estas y casi siempre tomamos la misma decisión: Ampliar nuestra muestra para ver hacia dónde se mueve esa p. Parece algo inocente. Al fin y al cabo, ¿cómo puede conducirnos a engaño basar nuestras conclusiones en más datos? Sin embargo, actuar así tiene sus riesgos. En principio, siguiendo rigurosamente los cánones de la metodología científica, antes de hacer un experimento deberíamos decidir cuántas observaciones vamos a realizar y después deberíamos creernos lo que salga de esa muestra. Hacer lo contrario, analizar los datos cuando tenemos parte de la muestra y ampliarla más o menos según lo que nos vayan diciendo esos análisis, es peligroso porque puede arrojar falsos positivos: Supone incrementar el riesgo de que esa p sea menor que 0.05 se deba al simple azar y no a que hayamos descubierto una diferencia realmente significativa. Pero el proceso no está libre de ambigüedades porque, para empezar, ¿cómo sabemos a priori cuál es el tamaño ideal para nuestra muestra?
En un interesantísimo artículo que acaba de publicarse en Psychological Science, Joseph Simmons, Leif Nelson y Uri Simonsohn, nos muestran hasta qué punto pueden ser dañinas estas prácticas y otras similares, tales como omitir información sobre algunas variables dependientes en favor de otras, decidir si realizar un análisis teniendo o sin tener en cuenta una covariable, o informar sólo de los grupos que mejor se ajustan a los resultados deseados. Mediante una simulación informática muestran que si los investigadores se permiten recurrir libremente a estas estrategias, las posibilidades de que los datos lleguen a reflejar relaciones inexistentes crecen de una forma vertiginosa. De hecho, llegan a estimar que recurriendo a la vez a todas ellas, la probabilidad de que una diferencia significativa refleje un falso positivo (que normalmente debería ser del 5%; eso es lo que significa precisamente la p de más arriba) puede llegar al 60.7%.
Por si estas simulaciones no fueran suficiente, los autores recurren a un argumento mucho más didáctico. Realizan dos experimentos en los que violando estas reglas demuestran que la gente se hace más joven (no que se sienta más joven, ¡sino que es más joven literalmente!) tras escuchar “When I’m sixty-four” de los Beatles que tras escuchar “Kalimba” una canción instrumental incluida en el Windows 7. En otras palabras, aunque utilicemos controles experimentales rigurosos y análisis estadísticos robustos y adecuados, permitirnos la libertad de ampliar muestra a nuestro antojo, seleccionar los grupos o las variables dependientes más favorables o realizar los análisis que nos parezcan mejores a posteriori, puede permitirnos demostrar cualquier cosa y su contraria. Esta conclusión viene a coincidir con la que hace unos años expresaba Ioannidis en un popular artículo cuyo nombre lo decía todo: Why most published research findings are false.
El artículo de Simmons y colaboradores concluye con una serie de recomendaciones a los investigadores y a los revisores de revistas científicas para reducir el peligro de obtener falsos positivos. Lo que sugieren, básicamente, se reduce a pedir a los autores que sean más transparentes con las medidas que realizan, con el número de grupos que utilizaron, con el criterio que siguieron a la hora de decidir el tamaño muestral y con los resultados que tienen cuando los análisis se realizan de diferentes maneras. Los revisores, lógicamente, tienen que asegurarse de que se cumpla con estos estándares. Pero también les lanza una recomendación importante: deberían ser más tolerantes con las imperfecciones de los resultados. Al fin y al cabo, si el experimento de más arriba se hubiera podido publicar con esa p = 0.057, la historia habría terminado ahí.
__________
Ioannidis, J. P. A. (2005). Why most published research findings are false. PLoS Medicine, 2, e124.
Cuando la evidencia científica es contradictoria
En todas las discusiones entre los defensores de una pseudociencia y sus adversarios resulta sorprendente comprobar cómo tanto uno como otro bando defienden tener la evidencia científica de su lado. Esto es particularmente frecuente en las discusiones sobre la eficacia de la homeopatía. Los defensores de esta “terapia” se defienden trayendo a colación los resultados de estudios científicos que observan un efecto beneficioso de la homeopatía, mientras que los escépticos invocan también a la propia ciencia para defender que la homeopatía es un fraude. Este tipo de situaciones invita a pensar que alguien miente. ¿O tal vez no?
Lo cierto es que en cualquier situación en la que el azar juegue un papel importante es perfectamente plausible que la evidencia científica arroje resultados tanto a favor como en contra de una determinada hipótesis. Lo interesante es ver qué sucede cuando se tiene en cuenta toda la evidencia disponible (en lugar de estudios aislados) e intentar encontrar qué variables pueden estar determinando que se observe uno u otro resultado.

Figura 1
En el caso de la homeopatía, disponemos de muchos y muy buenos meta-análisis que proporcionan esta información. Uno de mis favoritos es el publicado por Shang y colaboradores (2005) en The Lancet. Los resultados de ese estudio se pueden resumir con una gráfica como la que puede verse a la izquierda. (Confieso que son datos inventados; pero nadie me negará el parecido con la Figura 2 del artículo de Shang y colaboradores.)
Lo que este gráfico nos muestra es a) que efectivamente hay muchos estudios cuyo resultado sugiere que la homeopatía tiene un efecto terapéutico (puntos por encima de la línea 0), b) que efectivamente hay muchos estudios que muestran que la homeopatía no tuvo efectos (puntos cercanos a la línea 0), y c) que la principal diferencia entre unos y otros es la calidad metodológica del estudio (si se utilizó o no un control de doble ciego, cómo de grande era la muestra…). Si se trata de saber si la homeopatía es efectiva o no, con estos datos debería ser suficiente para obtener una respuesta: No. Los únicos estudios que muestran un efecto son los que tienen problemas metodológicos o muestras muy pequeñas. Cuando se consideran sólo los resultados de los mejores estudios, el efecto terapéutico no es significativamente diferente de 0.
Sin embargo, la gráfica anterior me interesa por un segundo motivo. Es de sentido común que los estudios que se basan en muestras más grandes arrojen datos más seguros. (Por eso ningún científico serio se cree del todo los resultados de ningún estudio con muestras pequeñas.) Cuando las muestras son pequeñas lo normal es que los resultados estén muy influidos por los caprichos del azar y sean por tanto muy variables. Sin embargo, esto no explica por qué en la gráfica anterior se observan resultados sistemáticamente positivos con muestras pequeñas. En otras palabras, ahí no vemos resultados variables, sino resultados consistentemente positivos. ¿A qué podría deberse esto? En realidad se puede deber a muy pocas cosas. Y lo más probable es que se deba a lo siguiente.
Imagina que en lugar de discutir sobre si la homeopatía funciona o no, estamos discutiendo sobre si una moneda está trucada o no. Tú dices que sí lo está, que salen más caras que cruces. Yo digo que no lo está. Así que para descubrir quién tiene razón probamos a tirar la moneda al aire unas cuantas veces. A veces, tiramos la moneda al aire 10 veces y vemos qué pasa. Otras veces tiramos la moneda al aire 15 veces y vemos qué pasa. Otras veces 20, otras 25, y así sucesivamente. Probablemente, si organizamos estos datos en una gráfica como la anterior, obtendremos unos resultados similares a los de la Figura 2.

Figura 2
Es decir, que cuando hacemos tiradas cortas, los resultados son muy variables. A veces obtenemos una proporción de caras muy por encima o muy por debajo de 0.50, aunque la media tiende a mantenerse en 0.50. Cuando hacemos tiradas más largas, los resultados son menos variables: La proporción de caras oscila poco en torno a ese mismo 0.50. ¿Qué sugieren estos datos? Pues que la moneda no está trucada.
Ahora bien, imaginemos que hacemos este experimento de una forma un poco diferente. En primer lugar, imagina que no tenemos una simple curiosidad desinteresada por saber si la moneda está trucada o no, sino que nos jugamos algo en ello. Por ejemplo, tú has apostado 200 euros a que salen más caras que cruces y yo me apuesto lo mismo a que no. Imaginemos además que el encargado de tirar la moneda y ver qué sale eres tú. Lo haces en tu casa y me vas contando por teléfono lo que te sale. Yo voy apuntando lo que me dices en una hoja de Excel y al final tengo una gráfica como la Figura 3.

Figura 3
Así, de buenas a primeras, parece que en la mayor parte de las tiradas hemos sacado más caras que cruces. Parece que tú ganas. Estoy casi tentado de acercarme al cajero para sacar tus 200 euros, cuando caigo en la cuenta de que la Figura 3 es exactamente igual a la 2 salvo que faltan algunos datos contrarios a tu hipótesis. ¿No parece más bien que has ido probando la moneda en casa y me has comentado sólo los resultados de las tiradas que te favorecían?
Efectivamente, cuando tenemos datos como los que aparecen en las Figuras 1 ó 3 podemos sospechar con toda legitimidad que se está omitiendo información. Es decir que los resultados de los ensayos homeopáticos como los que aparecen en la Figura 1 sugieren que no se están publicando todos los datos. Probablemente existen ensayos clínicos con muestras pequeñas que también han encontrado efectos nulos (¡o incluso negativos!) para la homeopatía, pero estos datos nunca han visto la luz.
Por el ejemplo que he utilizado, muchos estarán interpretando que acuso a los investigadores de la homeopatía de esconder a propósito datos que van contra la propia homeopatía. Seguro que algunos lo hacen. Pero no creo que toda la cuestión se pueda achacar a la falta de honestidad científica, ni creo que sea el motivo más importante de esta omisión de datos. Como cualquier investigador sabe, es muy difícil que una revista se anime a publicar estudios cuyo resultado es nulo, estudios donde no se demuestra que algo sea diferente de otra cosa. De la misma forma que “perro muerde a hombre” no es noticia, normalmente demostrar que “el tratamiento A no funciona” o que “el efecto X no se observa” raramente despierta el interés de la comunidad. Yo mismo tengo un archivador repleto de experimentos con resultados de experimentos nulos que nunca serán dados a conocer. Si tuviera la más mínima esperanza de que pudieran publicarse en una revista medianamente digna, ahora mismo estaría exhumándolos del archivo .RAR en el que están enterrados. Pero sé que no es así.
El resultado de esta política es lo que se suele denominar publicación selectiva, un importante problema de la investigación científica. Como se publican sobre todo los estudios que obtienen resultados muy significativos, la literatura científica suele exagerar el tamaño real que tienen algunos efectos. El problema es tan ubicuo que algún estudio ha llegado a sugerir que podría haber publicación selectiva de artículos sobre publicación selectiva (Dubben & Beck-Bornholdt, 2005). Afortunadamente disponemos de las técnicas de meta-análisis para saber cuándo puede estar pasando y para calcular el tamaño del sesgo. ¡Larga vida al meta-análisis!
__________
