 Aunque llevaba meses deseando hacerme con un ejemplar del último libro de Nate Silver, The signal and the noise: The art and science of prediction, confieso que el primer contacto no me pareció muy alentador. Nada más mirar la foto del autor en la contraportada tuve la sensación de que alguien me susurraba al oído “perrea, perrea”. La cosa no mejoró cuando leí los primeros capítulos y descubrí que los temas que Silver había elegido para presentar su tesis eran de esos que despiertan un interés inversamente proporcional a la distancia que te separa de Oklahoma. El relato transcurre entre ligas de béisbol, elecciones a la presidencia de EE.UU., partidas de póker y otras pamplinas que posiblemente hagan la delicia del norteamericano medio, pero carecen de adeptos a este lado del charco.
Aunque llevaba meses deseando hacerme con un ejemplar del último libro de Nate Silver, The signal and the noise: The art and science of prediction, confieso que el primer contacto no me pareció muy alentador. Nada más mirar la foto del autor en la contraportada tuve la sensación de que alguien me susurraba al oído “perrea, perrea”. La cosa no mejoró cuando leí los primeros capítulos y descubrí que los temas que Silver había elegido para presentar su tesis eran de esos que despiertan un interés inversamente proporcional a la distancia que te separa de Oklahoma. El relato transcurre entre ligas de béisbol, elecciones a la presidencia de EE.UU., partidas de póker y otras pamplinas que posiblemente hagan la delicia del norteamericano medio, pero carecen de adeptos a este lado del charco.
Y sin embargo, el libro es una buenísima introducción a los problemas a los que se enfrenta cualquiera que quiera entender un sistema dinámico complejo y predecir su evolución. Entre otras cosas, el libro contiene la mejor explicación que conozco del concepto de overfitting. Si el lector no se ha encontrado nunca con esta palabreja, posiblemente creerá que el overfitting es el trastorno psiquiátrico que sufren las personas que van todos los días al gimnasio. Pero en realidad se trata de un concepto estadístico relacionado con cómo se ajusta un modelo a la realidad que pretende explicar y predecir. En principio, si uno desarrolla una teoría para explicar algo, cabría pensar que cuanto más se ajuste la teoría a los hechos, tanto mejor será la teoría. Pero en realidad puede suceder lo contrario: que una teoría sea mala precisamente porque se ajusta demasiado a los datos. Es entonces cuando decimos que el modelo tiene overfitting o sobreajuste. Veámoslo con el ejemplo que nos da el propio Nate Silver.
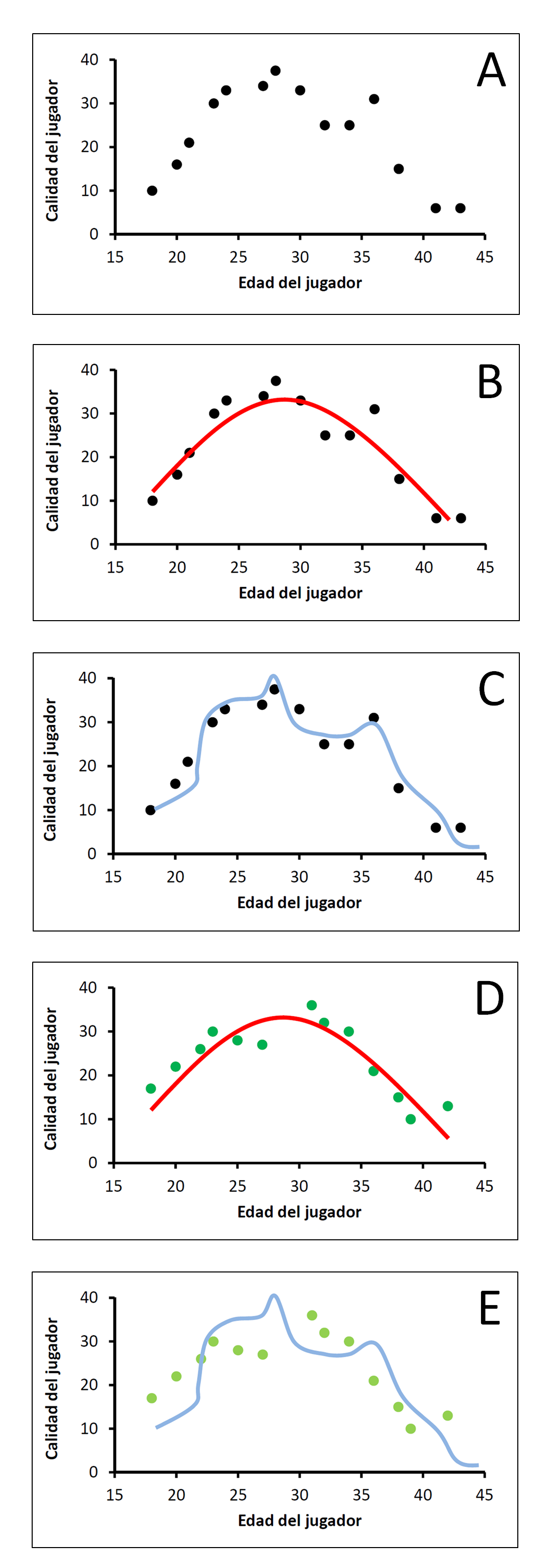 Imagina que queremos saber cómo evoluciona la calidad de un jugador de béisbol a medida que se va haciendo mayor. Lo primero que tenemos que hacer es recoger datos. Tras hacer algunas mediciones aquí y allá conseguimos la información que tenemos en el panel A. La forma más sencilla de explicar este patrón de resultados es asumir que la calidad de un jugador se incrementa progresivamente a medida que se va haciendo mayor hasta que llega un momento en el que la tendencia comienza a invertirse. Este modelo, al que llamaré Modelo 1, es el que aparece en el panel B. Como puede verse, el modelo no se ajusta a los datos a la perfección. De lo contrario todos los circulitos deberían estar exactamente en la línea. Sin embargo, el ajuste del modelo es aceptable. ¿Es posible diseñar un modelo con un ajuste todavía mejor? Por supuesto, el panel C muestra una línea alternativa que pasa mucho más cerca de todos los puntos. Llamemos a esta línea Modelo 2. La distancia media entre la línea y cada observación es menor para el Modelo 2 que para el Modelo 1. Ahora bien, ¿quiere eso decir que es un modelo mejor?
Imagina que queremos saber cómo evoluciona la calidad de un jugador de béisbol a medida que se va haciendo mayor. Lo primero que tenemos que hacer es recoger datos. Tras hacer algunas mediciones aquí y allá conseguimos la información que tenemos en el panel A. La forma más sencilla de explicar este patrón de resultados es asumir que la calidad de un jugador se incrementa progresivamente a medida que se va haciendo mayor hasta que llega un momento en el que la tendencia comienza a invertirse. Este modelo, al que llamaré Modelo 1, es el que aparece en el panel B. Como puede verse, el modelo no se ajusta a los datos a la perfección. De lo contrario todos los circulitos deberían estar exactamente en la línea. Sin embargo, el ajuste del modelo es aceptable. ¿Es posible diseñar un modelo con un ajuste todavía mejor? Por supuesto, el panel C muestra una línea alternativa que pasa mucho más cerca de todos los puntos. Llamemos a esta línea Modelo 2. La distancia media entre la línea y cada observación es menor para el Modelo 2 que para el Modelo 1. Ahora bien, ¿quiere eso decir que es un modelo mejor?
Tal vez no. El objetivo de una buena teoría no es sólo ajustarse bien a la evidencia que ya tenemos, sino también predecir los datos que podríamos observar en el futuro. Imagina que recabamos información sobre otros jugadores y que los circulitos verdes del panel D representan los resultados de estas nuevas observaciones. Estos datos siguen estando relativamente cerca de lo que predecía el Modelo 1. Sin embargo, el Modelo 2, que originalmente parecía ajustarse muy bien a los datos, ya no coincide de forma tan elegante con las nuevas observaciones.
En la terminología de Nate Silver, lo que le pasa al Modelo 2 es que no sólo trata de explicar la señal de la relación entre la edad y la calidad de un jugador, sino también el ruido aleatorio que inevitablemente contamina los datos. El modelo está tan ajustado a las observaciones que explica incluso lo que no debería explicar: la varianza que se debe al puro azar.
