Pruebe a hacer el siguiente experimento. Haga click sobre el cuadro de texto de Google y comience a escribir “replication crisis”. Con su habitual don de gentes, el buscador enseguida se ofrecerá a auto-completar el término de búsqueda. En ningún caso leerá “replication crisis in physics” o “replication crisis in biology”. No. Google es más listo que eso. Quienes han buscado esos términos en el pasado por lo general han terminado escribiendo “replication crisis in psychology”. Y así nos lo arroja a la cara el simpático rastreador de la web.
Pruebe a hacer el siguiente experimento. Haga click sobre el cuadro de texto de Google y comience a escribir “replication crisis”. Con su habitual don de gentes, el buscador enseguida se ofrecerá a auto-completar el término de búsqueda. En ningún caso leerá “replication crisis in physics” o “replication crisis in biology”. No. Google es más listo que eso. Quienes han buscado esos términos en el pasado por lo general han terminado escribiendo “replication crisis in psychology”. Y así nos lo arroja a la cara el simpático rastreador de la web.
El mundo de la psicología se ha hecho un hueco en todas las portadas con sus recientes casos de fraude, sus misteriosas incursiones en el mundo de lo paranormal y, más recientemente, la imposibilidad de replicar uno o dos de sus más famosos y audaces experimentos. La otra parte de esta historia, menos sensacionalista pero más reveladora, es que la psicología también está en la primera línea de combate contra todo aquello que amenace a la integridad de la ciencia, dentro y fuera de sus fronteras. Algunas de las propuestas más ingeniosas para detectar y medir el impacto de las malas prácticas científicas se las debemos a la propia comunidad de investigadores de las ciencias del comportamiento. Una de mis favoritas tiene que ver con el estudio de la llamada curva de valores p.
En la estadística tradicional se procede de una forma un tanto retorcida. Para demostrar que un efecto existe lo que uno hace es asumir que no existe y luego ver cómo de rara sería la evidencia que hemos recogido si se parte de ese supuesto. El parámetro que mide cómo de extraño sería un dato bajo el supuesto de que un efecto no existe es lo que llamamos valor p. (En rigor, lo que mide el valor p es cómo de probable es encontrar un valor tan alejado o más de lo que cabría esperar bajo el supuesto de que la hipótesis nula es cierta.) Para lo que aquí nos interesa, basta con tener en cuenta que, por convención, se considera que uno ha observado un efecto significativo si el valor p de ese efecto es inferior a 0.05. Un valor tan pequeño quiere decir que es muy poco probable que el efecto se deba al puro azar. Que posiblemente hay un efecto real tras esos datos.
Imagine que queremos saber si una píldora reduce el dolor de cabeza. Para ello, hacemos el siguiente experimento. Le pedimos a un grupo de 50 personas que tome esa píldora todos los días y que apunte en una libreta cuándo le duele la cabeza. A otro grupo de personas le pedimos que haga exactamente lo mismo, pero sin que ellos lo sepan le damos un placebo. Después de un par de meses les pedimos que nos envíen las libretas y observamos que a los que han tomado la píldora les ha dolido la cabeza una media de 10 días. Sin embargo a los que han tomado el placebo les ha dolido la cabeza una media de 15 días. ¿Quiere esto decir que la píldora funciona? Bueno. Pues parece que sí. Pero la verdad es que este resultado podría deberse al puro azar. Para saber hasta qué punto se puede deber al azar o no, hacemos un análisis estadístico y nos dice que el valor p que obtenemos al comparar los grupos es, por ejemplo, 0.03. Como ese valor es inferior a 0.05, consideraríamos poco probable que la diferencia entre ambos grupos se deba al simple azar.
Aquí viene lo interesante. ¿Qué pasaría si la píldora realmente funciona y hacemos ese experimento muchas veces? Sin duda, aunque la píldora sea efectiva, el azar también influirá en los resultados. De modo que no siempre obtendremos los mismos datos. Y los análisis estadísticos no siempre arrojarán el mismo valor p. Unas veces será más alto y otras más bajo. Si el experimento se repitiera una y otra vez, la distribución de los valores p que obtendríamos debería parecerse a una curva exponencial en la que la mayor parte de los valores p serían muy pequeños y, sin embargo, habría relativamente menos experimentos que arrojaran valores p cercanos a 0.05. Esa gráfica, representando la distribución ideal de los valores p es lo que se denomina curva-p.
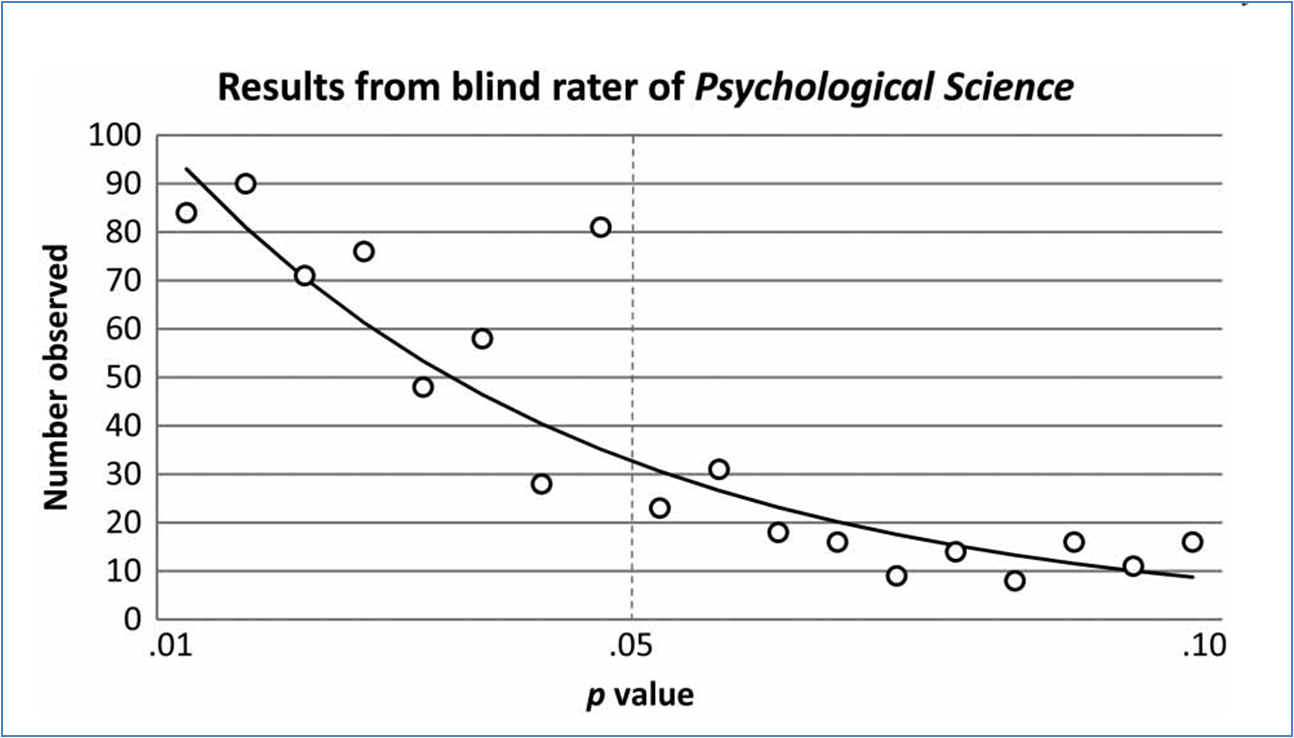
 En condiciones normales, si uno coge los artículos que se publican en las revistas y registra sus valores p, deberían seguir una distribución similar a la que muestra esa curva. Pero, como ya puede imaginarse, no es eso lo que sucede. En el caso de algunas revistas la distribución real de valores p se aleja muy sustancialmente de la distribución ideal. En un estudio reciente, Masicampo y Lalande (2012) trazaron la curva de valores p de tres revistas extremadamente importantes en el ámbito de la psicología: Journal of Experimental Psychology: General, Journal of Personality and Social Psychology y Psychological Science. Los resultados indicaron que en los tres casos los valores p observados diferían significativamente de la distribución ideal. En concreto, en todas ellas había un número sospechosamente alto de valores inmediatamente inferiores a 0.05, que según la distribución ideal deberían ser los más infrecuentes. Como puede verse en la figura de la izquierda, en el caso de Psychological Science, la prevalencia de estos valores apenas significativos es realmente escalofriante.
En condiciones normales, si uno coge los artículos que se publican en las revistas y registra sus valores p, deberían seguir una distribución similar a la que muestra esa curva. Pero, como ya puede imaginarse, no es eso lo que sucede. En el caso de algunas revistas la distribución real de valores p se aleja muy sustancialmente de la distribución ideal. En un estudio reciente, Masicampo y Lalande (2012) trazaron la curva de valores p de tres revistas extremadamente importantes en el ámbito de la psicología: Journal of Experimental Psychology: General, Journal of Personality and Social Psychology y Psychological Science. Los resultados indicaron que en los tres casos los valores p observados diferían significativamente de la distribución ideal. En concreto, en todas ellas había un número sospechosamente alto de valores inmediatamente inferiores a 0.05, que según la distribución ideal deberían ser los más infrecuentes. Como puede verse en la figura de la izquierda, en el caso de Psychological Science, la prevalencia de estos valores apenas significativos es realmente escalofriante.
¿A qué se debe esta distribución anómala de valores p? A que algo huele a podrido en Dinamarca, claro. Estas distribuciones son probablemente el producto de muchas prácticas malsanas en el mundo de la investigación. Una buena parte de la responsabilidad la tienen las propias revistas y sus equipos editoriales. Si un estudio tiene un valor p de 0.049 se publica, pero si tiene un valor p de 0.051 no se publica. No es significativo. ¿Se hace esto porque hay alguna barrera infranqueable entre lo que es mayor o menor de 0.05? En absoluto. El umbral del 0.05 es una pura convención social. La mayor parte de las veces la diferencia entre un estudio con una p = 0.045 y otro con p = 0.055 es el puro azar y nada más. Pero para el investigador hay una diferencia fundamental entre ambos: obtener un 0.045 significa que su trabajo cae dentro de lo convencionalmente aceptado y por tanto se publicará. Y publicarlo supone que el trabajo que ha hecho será conocido y reconocido por la comunidad científica. Y cuando quiera presentarse a una plaza de profesor o pedir un proyecto de investigación su contribución a la ciencia será tenida en cuenta. Obtener un 0.055 significa que el trabajo cae dentro de lo convencionalmente inaceptable. Costará horrores publicarlo o, más probablemente, no se publicará. La comunidad científica no lo conocerá y difícilmente se le valorará al investigador por haber dedicado meses o años de su trabajo a ese estudio.
Lógicamente el investigador que obtienen un valor p feo no se mete las manos en los bolsillos y se queda esperando a tener más suerte con su siguiente proyecto de investigación. Es muy probable que empiece a juguetear con los datos para ver si hay algo que pueda explicar por qué sus resultados no son significativos. Por ejemplo, es posible que descubra que uno de sus pacientes en el grupo que tomaba la píldora tenía un cáncer terminal y que por eso le dolía la cabeza mucho más que al resto. Al meter a ese participante en los análisis se está inflando el dolor de cabeza medio que sienten los miembros del grupo experimental que toma la píldora. ¡Normal que las diferencias no sean del todo significativas! Lo más probable es que el investigador elimine a este participante de la muestra dando por sentado que es un caso anómalo que está contaminando los resultados. Parece algo tan de sentido común que cuesta ver dónde está el problema en hacerlo. Pues bien, el problema es que si ese participante anómalo hubiera resultado estar en el grupo control, el que tomaba el placebo, posiblemente el investigador ni se habría dado cuenta de que existía. Los resultados habrían parecido bonitos desde el principio: habría encontrado las diferencias significativas que esperaba.
En otras palabras, los datos feos tienen más probabilidad de mantenerse en el estudio cuando favorecen la hipótesis del investigador que cuando van en contra. Y lo que esto supone es que si el azar resulta ir en contra del investigador se hacen más intentos por corregirlo que si la suerte conspira para “ayudarle”. Todas estas prácticas de análisis de los datos que permiten al investigador inclinar la balanza a su favor es lo que en la literatura se conoce como p-hacking. Todas ellas suponen una importante amenaza para la integridad de los resultados científicos porque incrementan la probabilidad de que un resultado aparentemente significativo refleje en realidad un falso positivo.
¿Cómo solucionar el problema? Lo cierto es que afortunadamente pueden ensayarse varias soluciones. Pero eso ya es una historia para otra entrada en este blog…
__________
Masicampo, E. J., & Lalande, D. R. (2012). A peculiar prevalance of p values just below .05. Quarterly Journal of Experimental Psychology, 65, 2271-2279.