Josep Marco-Pallarés y Juan Lupiáñez tuvieron la amabilidad de invitarme a dar un seminario en los másteres que dirigen en la Universitat de Barcelona y la Universidad de Granada, respectivamente. Intenté convencer a los estudiantes de que no deben creerse todo lo que lean en un artículo y les enseñé algunas herramientas estadísticas sencillas que permiten evaluar críticamente cómo de creíbles son los resultados de un estudio. Entre otras cosas, vimos cómo analizar la distribución de valores p, cómo hacer un funnel plot y cómo usar el test de exceso de resultados significativos. Si te interesan estos temas, puedes encontrar información sobre todas estas técnicas en las diapositivas del curso, incluyendo el código necesario para hacer los análisis en R y enlaces a otras aplicaciones online para detectar sesgos.
Tag Archives: p-hacking
¿Sirve de algo entrenar la memoria de trabajo?
Dice la canción que tres cosas hay en la vida: salud, dinero y amor. Si hubiera que añadir una cuarta, mi voto va para la memoria de trabajo (MT). Es uno de esos constructos mágicos que parece predecirlo casi todo en la vida: capacidad lectora, rendimiento en matemáticas, aprendizaje de idiomas… De todo. Ante esta evidencia, es tentador pensar que entrenando la MT se podría desarrollar cualquier capacidad cognitiva. Si esto fuera cierto, el rendimiento intelectual podría mejorarse fácilmente mediante sencillos juegos de ordenador que nos obligaran a ejercitar la MT. Y, en efecto, decenas de estudios parecen (o parecían) sugerir que estos programas de entrenamiento funcionan. Sin embargo, un artículo recién publicado por Monica Melby-Lervåg, Thomas Redick y Charles Hulme desafía esta conclusión.
El artículo presenta un meta-análisis de 145 comparaciones experimentales publicadas en 87 artículos. Los resultados pueden resumirse en la figura que reproduzco bajo estas líneas. La columna de la derecha diferencia tres tipos de estudios, dependiendo de si se comprueba el efecto del entrenamiento en habilidades similares a las entrenadas (near-transfer effects), parcialmente similares a las entrenadas (intermediate-transfer effects) o totalmente diferentes a las entrenadas (far-transfer effects). Un primer patrón que puede observarse es que los efectos sólo son grandes en las dos primeras categorías. Entre los estudios que exploran el efecto del entrenamiento sobre habilidades lejanas, los efectos son siempre cercanos a cero.

La figura también clasifica los estudios en función de si utilizan un grupo de control “no tratado” o un grupo de control “tratado”. Los primeros son estudios donde los participantes del grupo de control no realizan ninguna actividad mientras los participantes del grupo experimental reciben el tratamiento. Como puede verse en la figura, los estudios que utilizan este tipo de grupo control pasivo son los que arrojan resultados más prometedores. Por desgracia, este tipo de grupo de control deja mucho que desear. Sería como comprobar la eficacia de una medicina utilizando como control a un grupo de personas que no consume ningún medicamento alternativo, ni siquiera un placebo.
 El resultado más interesante del artículo, a mi juicio, es el análisis de la distribución de valores-p. En cualquier área de investigación “sana”, donde se exploran efectos reales, la distribución de valores-p suele mostrar asimetría a la derecha. Esto es, hay muchos más estudios con valores-p entre 0.00 y 0.01 que entre 0.04 y 0.05. La gráfica 3 del artículo, que reproduzco a la izquierda, muestra justo el patrón contrario entre los estudios que utilizaron controles “tratados”. Este tipo de distribución plana -o incluso con asimetría a la izquierda- es el que suele observarse en presencia de falsos positivos. De hecho, aunque los autores son demasiado benévolos para discutir esta posibilidad, la asimetría a la izquierda sugiere que estos estudios podrían estar sesgados por cierta dosis de p-hacking. Es decir, que los datos podrían haberse analizado una y otra vez de diversas maneras hasta que, por azar, se obtuvieron resultados significativos.
El resultado más interesante del artículo, a mi juicio, es el análisis de la distribución de valores-p. En cualquier área de investigación “sana”, donde se exploran efectos reales, la distribución de valores-p suele mostrar asimetría a la derecha. Esto es, hay muchos más estudios con valores-p entre 0.00 y 0.01 que entre 0.04 y 0.05. La gráfica 3 del artículo, que reproduzco a la izquierda, muestra justo el patrón contrario entre los estudios que utilizaron controles “tratados”. Este tipo de distribución plana -o incluso con asimetría a la izquierda- es el que suele observarse en presencia de falsos positivos. De hecho, aunque los autores son demasiado benévolos para discutir esta posibilidad, la asimetría a la izquierda sugiere que estos estudios podrían estar sesgados por cierta dosis de p-hacking. Es decir, que los datos podrían haberse analizado una y otra vez de diversas maneras hasta que, por azar, se obtuvieron resultados significativos.
Estos resultados revisten una especial importancia para el diseño de intervenciones educativas para niños con problemas de aprendizaje. Entre algunos profesionales comenzaba a cuajar la idea de que estos problemas podían paliarse mediante el entrenamiento de la MT. Los resultados de este meta-análisis sugieren que este tipo de prácticas están seguramente avocadas al fracaso.
__________
Melby-Lervag, M., Redick, T. S., & Hulme, C. (2016). Working memory training does not improve performance on measures of intelligence or other measures of “far transfer”: Evidence from a meta-analytic review. Perspectives on Psychological Science, 11, 512-534.
Poniendo en contexto la replicabilidad de la psicología
Desde que se publicaron los resultados del Reproducibility Project: Psychology (RPP) las actitudes de la comunidad científica se han dividido entre quienes creen que es necesario cambiar radicalmente la forma en la que se hace investigación en nuestra disciplina y quienes consideran que la situación no es tan mala y que los métodos que se han venido utilizando hasta ahora han funcionado razonablemente bien. A falta de términos mejores –y ya que estamos en plena campaña electoral– llamaré a los primeros reformistas y a los segundos conservadores.
Uno de los argumentos más frecuentemente esgrimidos por los conservadores es que el fracaso a la hora de replicar un fenómeno no quiere decir necesariamente que ese fenómeno no exista. Si acaso, una réplica fallida revela que ese fenómeno sólo aparece en circunstancias muy concretas y que, tan pronto como se cambia algo en un estudio, el efecto desaparece. Por ejemplo, si hacemos un estudio sobre las actitudes de los blancos hacia las personas de otras razas, es muy probable que los resultados sean muy diferentes en países como EE.UU. que en Holanda o Australia. Si alguien no consigue replicar en Holanda un resultado que se observó inicialmente en EE.UU. esto no quiere decir que el hallazgo original fuera falso sino, simplemente, que sólo puede detectarse en circunstancias muy concretas.
Un trabajo recién publicado en la prestigiosa PNAS sugiere que los resultados negativos del RPP podrían deberse en buena parte a las dificultades para recrear el contexto de los experimentos originales. Los autores de este estudio pidieron a tres investigadores que leyeran los abstracts de los 100 estudios que se habían intentado replicar en el RPP y que, en base únicamente a esos textos, juzgaran hasta qué punto los fenómenos estudiados podrían depender del contexto en el que tenía lugar el estudio. Por ejemplo, se les pedía que estimaran si los resultados podrían depender de que el estudio se realizara en un momento concreto (por ejemplo, tiempos de recesión), en una comunidad étnica, racial o cultural concreta (por ejemplo, mezcla de diferentes razas, culturas individualistas), o en un entorno rural o urbano, entre otros aspectos.
 Los autores del estudio tomaron estas estimaciones de la importancia del contexto y analizaron hasta qué punto ayudaban a predecir si un experimento se replicaría o no. Los resultados más importantes se muestran en la figura adjunta. Lo que aquí se muestra es que, después de controlar estadísticamente algunas de las variables más importantes (por ejemplo, la potencia estadística de la réplica, la “sorpresividad” del efecto en cuestión), la sensibilidad al contexto seguía explicando una parte importante de la varianza. Estos datos vienen a confirmar que manteniendo constantes todos los demás factores, algunos fenómenos son más sensibles al contexto que otros y esa mayor sensibilidad determina que puedan ser fácilmente replicados o no.
Los autores del estudio tomaron estas estimaciones de la importancia del contexto y analizaron hasta qué punto ayudaban a predecir si un experimento se replicaría o no. Los resultados más importantes se muestran en la figura adjunta. Lo que aquí se muestra es que, después de controlar estadísticamente algunas de las variables más importantes (por ejemplo, la potencia estadística de la réplica, la “sorpresividad” del efecto en cuestión), la sensibilidad al contexto seguía explicando una parte importante de la varianza. Estos datos vienen a confirmar que manteniendo constantes todos los demás factores, algunos fenómenos son más sensibles al contexto que otros y esa mayor sensibilidad determina que puedan ser fácilmente replicados o no.
 No es ningún secreto que mis simpatías se decantan hacia el lado de los reformistas. Aunque valoro este tipo de trabajos y puedo apreciar su contribución, inevitablemente me despiertan sospechas. Ya he contestado aquí a quienes argumentan que los intentos fallidos de replicar un experimento se deben atribuir a moderadores y variables contextuales. Mi argumentación es idéntica en este caso. Puedo entender que unos fenómenos sean más delicados que otros y que requieran un mayor esfuerzo por parte del investigador para recrear las condiciones ideales; pero este argumento deja sin explicar la clara evidencia de sesgos de publicación y de p-hacking en los estudios originales del RPP. Uno de las gráficas que mejor lo demuestra es esta distribución de valores z elaborada por Richard Kunert. Un experimento tiene resultados significativos cuando su z es mayor de 1.96. Como puede verse en este gráfico, las puntuaciones z de los estudios originales del RPP es extremadamente irregular, con un pico muy pronunciado justo alrededor de 2. Esta distribución sugiere que ha habido sesgos de publicación (los estudios con z < 1.96 se han borrado del mapa) o malas prácticas (los estudios con z < 1.96 se han reanalizado una y otra vez hasta que por arte de magia se ha obtenido una z > 1.96). Nada de esto quiere decir que los autores del estudio en PNAS se equivoquen. Pero sospecho que representa sólo una parte de la historia. Una parte que puede resultar reconfortante, pero que tal vez nos ayude poco a mejorar la ciencia que hacemos.
No es ningún secreto que mis simpatías se decantan hacia el lado de los reformistas. Aunque valoro este tipo de trabajos y puedo apreciar su contribución, inevitablemente me despiertan sospechas. Ya he contestado aquí a quienes argumentan que los intentos fallidos de replicar un experimento se deben atribuir a moderadores y variables contextuales. Mi argumentación es idéntica en este caso. Puedo entender que unos fenómenos sean más delicados que otros y que requieran un mayor esfuerzo por parte del investigador para recrear las condiciones ideales; pero este argumento deja sin explicar la clara evidencia de sesgos de publicación y de p-hacking en los estudios originales del RPP. Uno de las gráficas que mejor lo demuestra es esta distribución de valores z elaborada por Richard Kunert. Un experimento tiene resultados significativos cuando su z es mayor de 1.96. Como puede verse en este gráfico, las puntuaciones z de los estudios originales del RPP es extremadamente irregular, con un pico muy pronunciado justo alrededor de 2. Esta distribución sugiere que ha habido sesgos de publicación (los estudios con z < 1.96 se han borrado del mapa) o malas prácticas (los estudios con z < 1.96 se han reanalizado una y otra vez hasta que por arte de magia se ha obtenido una z > 1.96). Nada de esto quiere decir que los autores del estudio en PNAS se equivoquen. Pero sospecho que representa sólo una parte de la historia. Una parte que puede resultar reconfortante, pero que tal vez nos ayude poco a mejorar la ciencia que hacemos.
__________
Van Bavel, J. J., Mende-Siedlecki, P., Brady, W. J., & Reinero, D. A. (2016). Contextual sensitivity in scientific reproducibility. Proceedings of the National Academy of Sciences of the United States of America, 113, 6454-6459.
p-curves, p-hacking, and p-sychology
 Pruebe a hacer el siguiente experimento. Haga click sobre el cuadro de texto de Google y comience a escribir “replication crisis”. Con su habitual don de gentes, el buscador enseguida se ofrecerá a auto-completar el término de búsqueda. En ningún caso leerá “replication crisis in physics” o “replication crisis in biology”. No. Google es más listo que eso. Quienes han buscado esos términos en el pasado por lo general han terminado escribiendo “replication crisis in psychology”. Y así nos lo arroja a la cara el simpático rastreador de la web.
Pruebe a hacer el siguiente experimento. Haga click sobre el cuadro de texto de Google y comience a escribir “replication crisis”. Con su habitual don de gentes, el buscador enseguida se ofrecerá a auto-completar el término de búsqueda. En ningún caso leerá “replication crisis in physics” o “replication crisis in biology”. No. Google es más listo que eso. Quienes han buscado esos términos en el pasado por lo general han terminado escribiendo “replication crisis in psychology”. Y así nos lo arroja a la cara el simpático rastreador de la web.
El mundo de la psicología se ha hecho un hueco en todas las portadas con sus recientes casos de fraude, sus misteriosas incursiones en el mundo de lo paranormal y, más recientemente, la imposibilidad de replicar uno o dos de sus más famosos y audaces experimentos. La otra parte de esta historia, menos sensacionalista pero más reveladora, es que la psicología también está en la primera línea de combate contra todo aquello que amenace a la integridad de la ciencia, dentro y fuera de sus fronteras. Algunas de las propuestas más ingeniosas para detectar y medir el impacto de las malas prácticas científicas se las debemos a la propia comunidad de investigadores de las ciencias del comportamiento. Una de mis favoritas tiene que ver con el estudio de la llamada curva de valores p.
En la estadística tradicional se procede de una forma un tanto retorcida. Para demostrar que un efecto existe lo que uno hace es asumir que no existe y luego ver cómo de rara sería la evidencia que hemos recogido si se parte de ese supuesto. El parámetro que mide cómo de extraño sería un dato bajo el supuesto de que un efecto no existe es lo que llamamos valor p. (En rigor, lo que mide el valor p es cómo de probable es encontrar un valor tan alejado o más de lo que cabría esperar bajo el supuesto de que la hipótesis nula es cierta.) Para lo que aquí nos interesa, basta con tener en cuenta que, por convención, se considera que uno ha observado un efecto significativo si el valor p de ese efecto es inferior a 0.05. Un valor tan pequeño quiere decir que es muy poco probable que el efecto se deba al puro azar. Que posiblemente hay un efecto real tras esos datos.
Imagine que queremos saber si una píldora reduce el dolor de cabeza. Para ello, hacemos el siguiente experimento. Le pedimos a un grupo de 50 personas que tome esa píldora todos los días y que apunte en una libreta cuándo le duele la cabeza. A otro grupo de personas le pedimos que haga exactamente lo mismo, pero sin que ellos lo sepan le damos un placebo. Después de un par de meses les pedimos que nos envíen las libretas y observamos que a los que han tomado la píldora les ha dolido la cabeza una media de 10 días. Sin embargo a los que han tomado el placebo les ha dolido la cabeza una media de 15 días. ¿Quiere esto decir que la píldora funciona? Bueno. Pues parece que sí. Pero la verdad es que este resultado podría deberse al puro azar. Para saber hasta qué punto se puede deber al azar o no, hacemos un análisis estadístico y nos dice que el valor p que obtenemos al comparar los grupos es, por ejemplo, 0.03. Como ese valor es inferior a 0.05, consideraríamos poco probable que la diferencia entre ambos grupos se deba al simple azar.
Aquí viene lo interesante. ¿Qué pasaría si la píldora realmente funciona y hacemos ese experimento muchas veces? Sin duda, aunque la píldora sea efectiva, el azar también influirá en los resultados. De modo que no siempre obtendremos los mismos datos. Y los análisis estadísticos no siempre arrojarán el mismo valor p. Unas veces será más alto y otras más bajo. Si el experimento se repitiera una y otra vez, la distribución de los valores p que obtendríamos debería parecerse a una curva exponencial en la que la mayor parte de los valores p serían muy pequeños y, sin embargo, habría relativamente menos experimentos que arrojaran valores p cercanos a 0.05. Esa gráfica, representando la distribución ideal de los valores p es lo que se denomina curva-p.
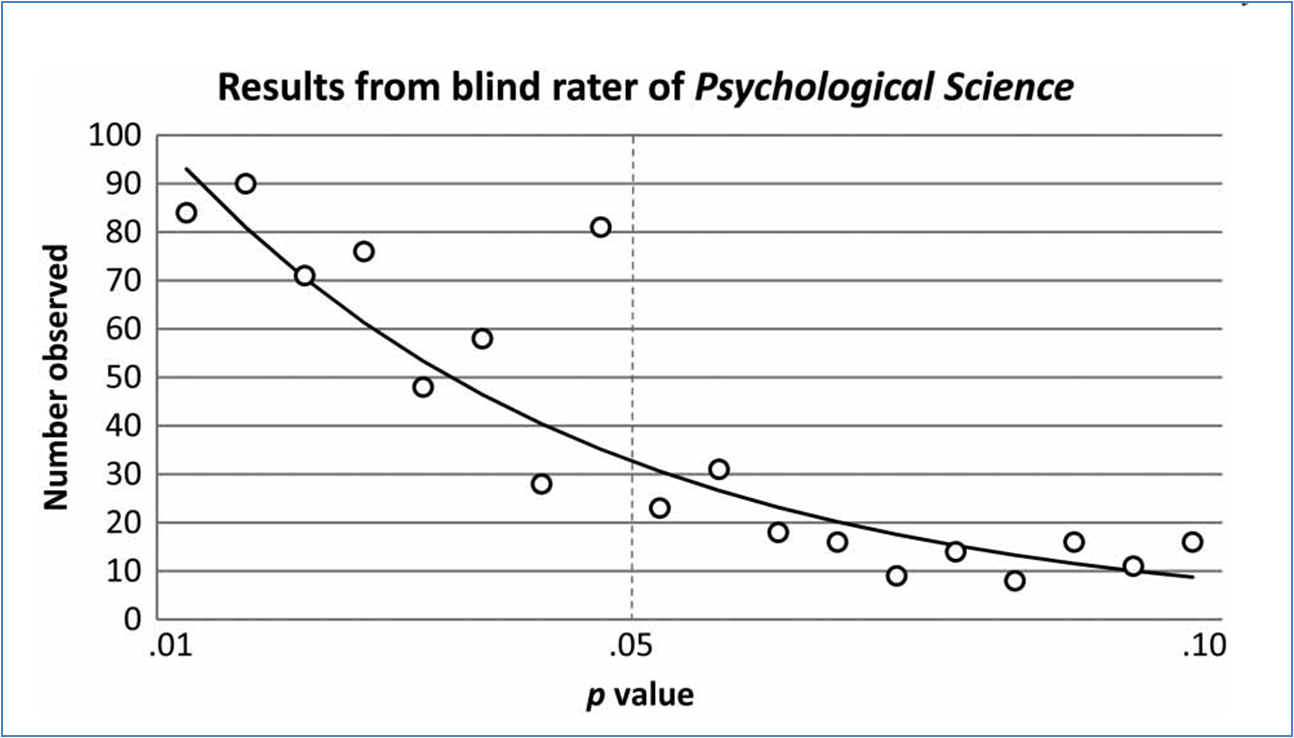 En condiciones normales, si uno coge los artículos que se publican en las revistas y registra sus valores p, deberían seguir una distribución similar a la que muestra esa curva. Pero, como ya puede imaginarse, no es eso lo que sucede. En el caso de algunas revistas la distribución real de valores p se aleja muy sustancialmente de la distribución ideal. En un estudio reciente, Masicampo y Lalande (2012) trazaron la curva de valores p de tres revistas extremadamente importantes en el ámbito de la psicología: Journal of Experimental Psychology: General, Journal of Personality and Social Psychology y Psychological Science. Los resultados indicaron que en los tres casos los valores p observados diferían significativamente de la distribución ideal. En concreto, en todas ellas había un número sospechosamente alto de valores inmediatamente inferiores a 0.05, que según la distribución ideal deberían ser los más infrecuentes. Como puede verse en la figura de la izquierda, en el caso de Psychological Science, la prevalencia de estos valores apenas significativos es realmente escalofriante.
En condiciones normales, si uno coge los artículos que se publican en las revistas y registra sus valores p, deberían seguir una distribución similar a la que muestra esa curva. Pero, como ya puede imaginarse, no es eso lo que sucede. En el caso de algunas revistas la distribución real de valores p se aleja muy sustancialmente de la distribución ideal. En un estudio reciente, Masicampo y Lalande (2012) trazaron la curva de valores p de tres revistas extremadamente importantes en el ámbito de la psicología: Journal of Experimental Psychology: General, Journal of Personality and Social Psychology y Psychological Science. Los resultados indicaron que en los tres casos los valores p observados diferían significativamente de la distribución ideal. En concreto, en todas ellas había un número sospechosamente alto de valores inmediatamente inferiores a 0.05, que según la distribución ideal deberían ser los más infrecuentes. Como puede verse en la figura de la izquierda, en el caso de Psychological Science, la prevalencia de estos valores apenas significativos es realmente escalofriante.
¿A qué se debe esta distribución anómala de valores p? A que algo huele a podrido en Dinamarca, claro. Estas distribuciones son probablemente el producto de muchas prácticas malsanas en el mundo de la investigación. Una buena parte de la responsabilidad la tienen las propias revistas y sus equipos editoriales. Si un estudio tiene un valor p de 0.049 se publica, pero si tiene un valor p de 0.051 no se publica. No es significativo. ¿Se hace esto porque hay alguna barrera infranqueable entre lo que es mayor o menor de 0.05? En absoluto. El umbral del 0.05 es una pura convención social. La mayor parte de las veces la diferencia entre un estudio con una p = 0.045 y otro con p = 0.055 es el puro azar y nada más. Pero para el investigador hay una diferencia fundamental entre ambos: obtener un 0.045 significa que su trabajo cae dentro de lo convencionalmente aceptado y por tanto se publicará. Y publicarlo supone que el trabajo que ha hecho será conocido y reconocido por la comunidad científica. Y cuando quiera presentarse a una plaza de profesor o pedir un proyecto de investigación su contribución a la ciencia será tenida en cuenta. Obtener un 0.055 significa que el trabajo cae dentro de lo convencionalmente inaceptable. Costará horrores publicarlo o, más probablemente, no se publicará. La comunidad científica no lo conocerá y difícilmente se le valorará al investigador por haber dedicado meses o años de su trabajo a ese estudio.
Lógicamente el investigador que obtienen un valor p feo no se mete las manos en los bolsillos y se queda esperando a tener más suerte con su siguiente proyecto de investigación. Es muy probable que empiece a juguetear con los datos para ver si hay algo que pueda explicar por qué sus resultados no son significativos. Por ejemplo, es posible que descubra que uno de sus pacientes en el grupo que tomaba la píldora tenía un cáncer terminal y que por eso le dolía la cabeza mucho más que al resto. Al meter a ese participante en los análisis se está inflando el dolor de cabeza medio que sienten los miembros del grupo experimental que toma la píldora. ¡Normal que las diferencias no sean del todo significativas! Lo más probable es que el investigador elimine a este participante de la muestra dando por sentado que es un caso anómalo que está contaminando los resultados. Parece algo tan de sentido común que cuesta ver dónde está el problema en hacerlo. Pues bien, el problema es que si ese participante anómalo hubiera resultado estar en el grupo control, el que tomaba el placebo, posiblemente el investigador ni se habría dado cuenta de que existía. Los resultados habrían parecido bonitos desde el principio: habría encontrado las diferencias significativas que esperaba.
En otras palabras, los datos feos tienen más probabilidad de mantenerse en el estudio cuando favorecen la hipótesis del investigador que cuando van en contra. Y lo que esto supone es que si el azar resulta ir en contra del investigador se hacen más intentos por corregirlo que si la suerte conspira para “ayudarle”. Todas estas prácticas de análisis de los datos que permiten al investigador inclinar la balanza a su favor es lo que en la literatura se conoce como p-hacking. Todas ellas suponen una importante amenaza para la integridad de los resultados científicos porque incrementan la probabilidad de que un resultado aparentemente significativo refleje en realidad un falso positivo.
¿Cómo solucionar el problema? Lo cierto es que afortunadamente pueden ensayarse varias soluciones. Pero eso ya es una historia para otra entrada en este blog…
__________
Masicampo, E. J., & Lalande, D. R. (2012). A peculiar prevalance of p values just below .05. Quarterly Journal of Experimental Psychology, 65, 2271-2279.
