Dirk Smeesters y Lawrence Sanna protagonizaron dos de los casos más sonados de fraude científico del pasado 2012. En un breve artículo que acaba de publicarse en Psychological Science, Uri Simonsohn nos revela cómo descubrió que estos dos autores se habían inventado datos, todo ello sin recurrir más que a un poco de estadística elemental y a una gran dosis de ingenio. Se trata en ambos casos de experimentos sobre el llamado priming social, un misterioso efecto investigado por psicólogos sociales según el cual comportamientos tan complejos como la conducta altruista o incluso el rendimiento en un test de cultura general pueden verse influidos por estímulos sutiles de cuyo efecto apenas somos conscientes (sic).
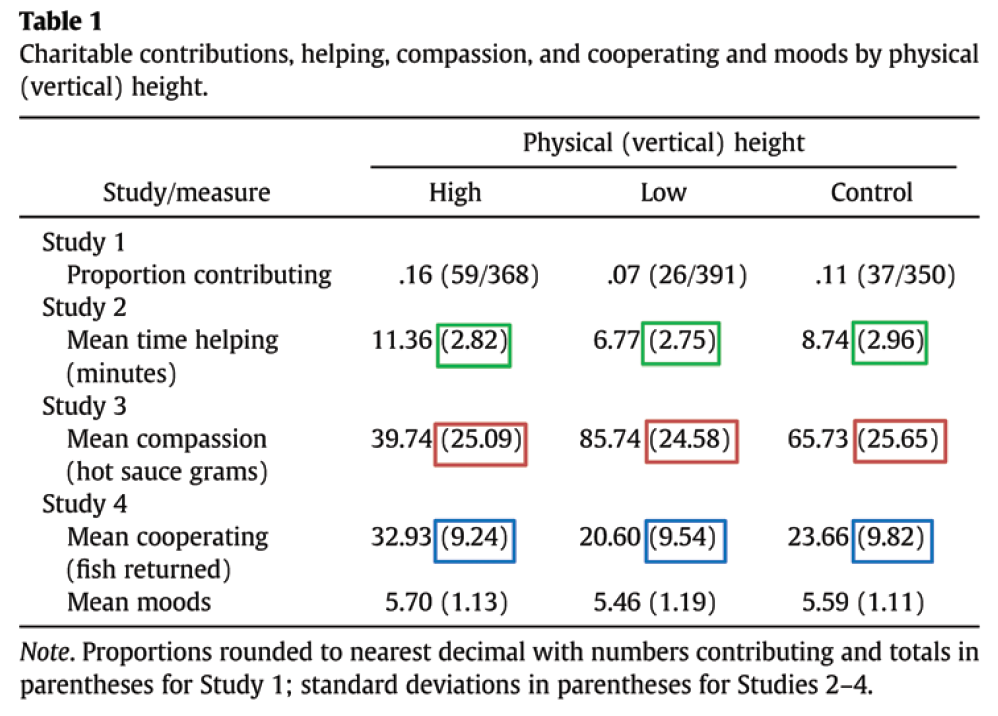 En el caso de Lawrence Sanna, el artículo crítico demostraba, presuntamente, que las personas eran más generosas cuando estaban sobre el escenario de un teatro, lo que sería compatible con la idea de que el comportamiento moral se asocia al concepto más abstracto de elevación (sic). Al ver la tabla de resultados que reproduzco aquí al lado, Simonsohn reparó en que algunos datos eran asombrosamente “bonitos”, imposiblemente “bonitos”. En concreto, dentro de cada experimento las desviaciones típicas (resaltadas aquí con cuadrados de colores) eran sorprendentemente similares. Mediante una sencilla simulación, Simonsohn comprobó que incluso asumiendo que las desviaciones típicas de cada grupo provinieran realmente de una población donde las desviaciones típicas son idénticas, la probabilidad de obtener tres muestras con desviaciones típicas tan cercanas es minúscula. Cuando Simonsohn pidió a los autores los datos originales del estudio, repitió sus simulaciones pero esta vez partiendo de los propios datos, mediante una técnica conocida como bootstrapping. Incluso así, la mayor parte de las simulaciones arrojaban desviaciones típicas más diferentes que las que se publicaron en el estudio de Sanna y colaboradores. Más aún, Simonsohn hizo mediciones similares en otros artículos del área, observando en cada caso cómo de diferentes tendían a ser las desviaciones típicas en las diferentes condiciones de este tipo de experimentos. Comparadas con las diferencias habituales, las que aparecen en los estudio de Sanna son insignificantes.
En el caso de Lawrence Sanna, el artículo crítico demostraba, presuntamente, que las personas eran más generosas cuando estaban sobre el escenario de un teatro, lo que sería compatible con la idea de que el comportamiento moral se asocia al concepto más abstracto de elevación (sic). Al ver la tabla de resultados que reproduzco aquí al lado, Simonsohn reparó en que algunos datos eran asombrosamente “bonitos”, imposiblemente “bonitos”. En concreto, dentro de cada experimento las desviaciones típicas (resaltadas aquí con cuadrados de colores) eran sorprendentemente similares. Mediante una sencilla simulación, Simonsohn comprobó que incluso asumiendo que las desviaciones típicas de cada grupo provinieran realmente de una población donde las desviaciones típicas son idénticas, la probabilidad de obtener tres muestras con desviaciones típicas tan cercanas es minúscula. Cuando Simonsohn pidió a los autores los datos originales del estudio, repitió sus simulaciones pero esta vez partiendo de los propios datos, mediante una técnica conocida como bootstrapping. Incluso así, la mayor parte de las simulaciones arrojaban desviaciones típicas más diferentes que las que se publicaron en el estudio de Sanna y colaboradores. Más aún, Simonsohn hizo mediciones similares en otros artículos del área, observando en cada caso cómo de diferentes tendían a ser las desviaciones típicas en las diferentes condiciones de este tipo de experimentos. Comparadas con las diferencias habituales, las que aparecen en los estudio de Sanna son insignificantes.
El segundo caso es una investigación similar de los datos de varios experimentos de Smeesters. En el primero de ellos “descubrieron” que los participantes rendían más en una prueba de cultura general si antes habían tenido que escribir sobre Einstein que si lo habían hecho sobre Kate Moss (sic). Pero (atención) ese efecto sólo aparecía si las instrucciones del experimento se daban en una carpeta azul (sic) y no si se daban en una carpeta roja (sic), porque (redoble de tambor) el rojo produce evitación y el azul produce aproximación (sicn). En el caso de este estudio eran las medias, y no las desviaciones típicas, las que se parecían demasiado. Tanto que las simulaciones basadas en los supuestos datos brutos del estudio arrojaban una probabilidad de entre 0.0003 y 0.00018 de obtener unas medias tan parecidas o más.
Indagando en los datos sobre otros estudios del mismo autor, Simonsohn descubrió más irregularidades de este tipo, algunas de ellas francamente ingeniosas. Una de ellas se basa en la observación de que las personas somos muy malas generando eventos aleatorios. Si nos piden que generemos secuencias de caras y cruces que podrían surgir de lanzar una moneda al aire, la mayor parte de las veces alternaremos entre caras y cruces y casi nunca propondremos una secuencia cara-cara-cara-cara. De hecho, predeciremos este tipo de repeticiones con mucha menos frecuencia de la que realmente suceden en la naturaleza. Siguiendo la misma lógica, si alguien se está inventando datos, es probable que los números que se le vienen a la cabeza incluyan menos repeticiones de las que cabría esperar por azar. Esto se cumple también en algunos de los experimentos de Smeesters, donde los valores modales del estudio se repiten tan poco que uno sólo esperaría menos repeticiones en entre 21 y 93 de cada 100.000 simulaciones. Tirando del mismo hilo, observó que en otro experimento en el que los participantes tenían que decir cuánto pagarían por unas camisetas, los participantes utilizaron menos múltiplos de 5 de lo que es normal en este tipo de estudios. Muchísimos menos. Menos también que cuando el propio Simonsohn intentó replicar el experimento original de Smeesters.
El resultado de esta peculiar operación anti-corrupción científica no es sólo que dos científicos nunca volverán a inventarse datos. Más importante que eso es que estas ideas se añaden al creciente número de estrategias con las que ahora podemos detectar casos similares de fraude. Cabe destacar también que este tipo de trampas son más fáciles de detectar si uno dispone del archivo de datos en el que se basa un estudio. Tal vez sea hora de plantearse si no deberíamos hacer públicos los datos de todas las publicaciones científicas.
__________

Esto en el mundo de la seguridad informática se llamaría algo así como “reversing malicious papers for phun and prophit” xD ¡Chulísimo! :)
Totalmente de acuerdo! Es un crack el Uri Simonsohn. Me encanta! Tiene un paper a punto de salir en JEPGen, si no ha salido ya, que también va a dar qué hablar. A ver si tengo tiempo de escribir un resumen aquí.
A mí casi me sorprende más que se publiquen esos papers con conceptos tan “metafísicos”… Y desde luego que estoy a favor no sé si de la directa publicación de las bases de datos, pero sí al menos de que junto al manuscrito en word se adjunte la base de datos en el envío para publicación de los papers… De todos modos, estos casos “cantan” por lo curioso de los resultados y por la conclusiones. Conque en otros papers de resultados menos ambiciosos o trascendentes, ¿cuánto fraude habrá sin descubrir?.
Pufff, a saber! Lo que sí es cierto es que cada vez hay más herramientas para detectarlo. Además de lo que aquí menciona Simonsohn, en los últimos años se ha publicado cómo detectar sesgos de publicación mediante estimaciones del poder estadístico (Francis Greg) y mediante curvas-p (algo que el propio Simonsohn acaba de publicar). Vamos, que cada vez se lo van a poner más difícil a esta gente. En relación a lo esotérico de estos estudios, no puedo estar más de acuerdo. Lo curioso es que este tipo de cosas sigue ocupando decenas de páginas de cualquier manual de cognición social. No parece que la comunidad académica esté dudando de estos estudios tanto como debería…